LoRA: Fine-Tuning Large Models with Low-Rank Updates
Fine-tuning a large model is conceptually simple: start from a pretrained checkpoint, run gradient descent on downstream data, and save the adapted model. The difficulty is that modern checkpoints are too large for this workflow to be cheap. Updating every parameter requires large optimizer states, large gradients, and large checkpoints. If every task needs a full model copy, storage and serving quickly become the bottleneck.
LoRA, short for Low-Rank Adaptation, changes the fine-tuning problem from “learn a new version of the whole model” to “learn a small residual update for selected weight matrices.” The pretrained model stays frozen. The trainable part is a pair of low-rank matrices that can be stored, shared, merged, or swapped much more cheaply than a full checkpoint.
This post is based mainly on the original LoRA paper and the later QLoRA paper. The figures below are converted from the papers’ arXiv LaTeX source.
The Problem LoRA Solves
Consider a transformer model with a linear projection:
\[h = Wx\]In full fine-tuning, the optimizer updates (W) directly. This gives maximum freedom, but it is expensive in three ways.
First, the optimizer must store training states for many parameters. Adam-style optimizers commonly need multiple auxiliary tensors per trainable parameter, so the memory footprint is much larger than the checkpoint size alone.
Second, each adapted model becomes large. If the base model is 7B, 13B, or 70B parameters, then a full fine-tuned checkpoint is essentially another model of similar size. A deployment with many domains or customers becomes a checkpoint management problem.
Third, serving variants is awkward. If each task requires a separate full checkpoint, batching across tasks, switching behavior, and rolling out updates become operationally heavy.
LoRA starts from a practical hypothesis: the useful downstream change may not need the full rank of the original matrix.
The Low-Rank Update
Let (W_0) be a frozen pretrained weight matrix. Full fine-tuning learns a dense update (\Delta W):
\[W' = W_0 + \Delta W\]LoRA does not learn a full (\Delta W). It parameterizes the update as the product of two smaller matrices:
\[\Delta W = BA\]If (W_0 \in \mathbb{R}^{d \times k}), then a full update has (d \times k) trainable parameters. A LoRA update with rank (r) has roughly (r(d+k)) trainable parameters. When (r) is small, this is much cheaper.
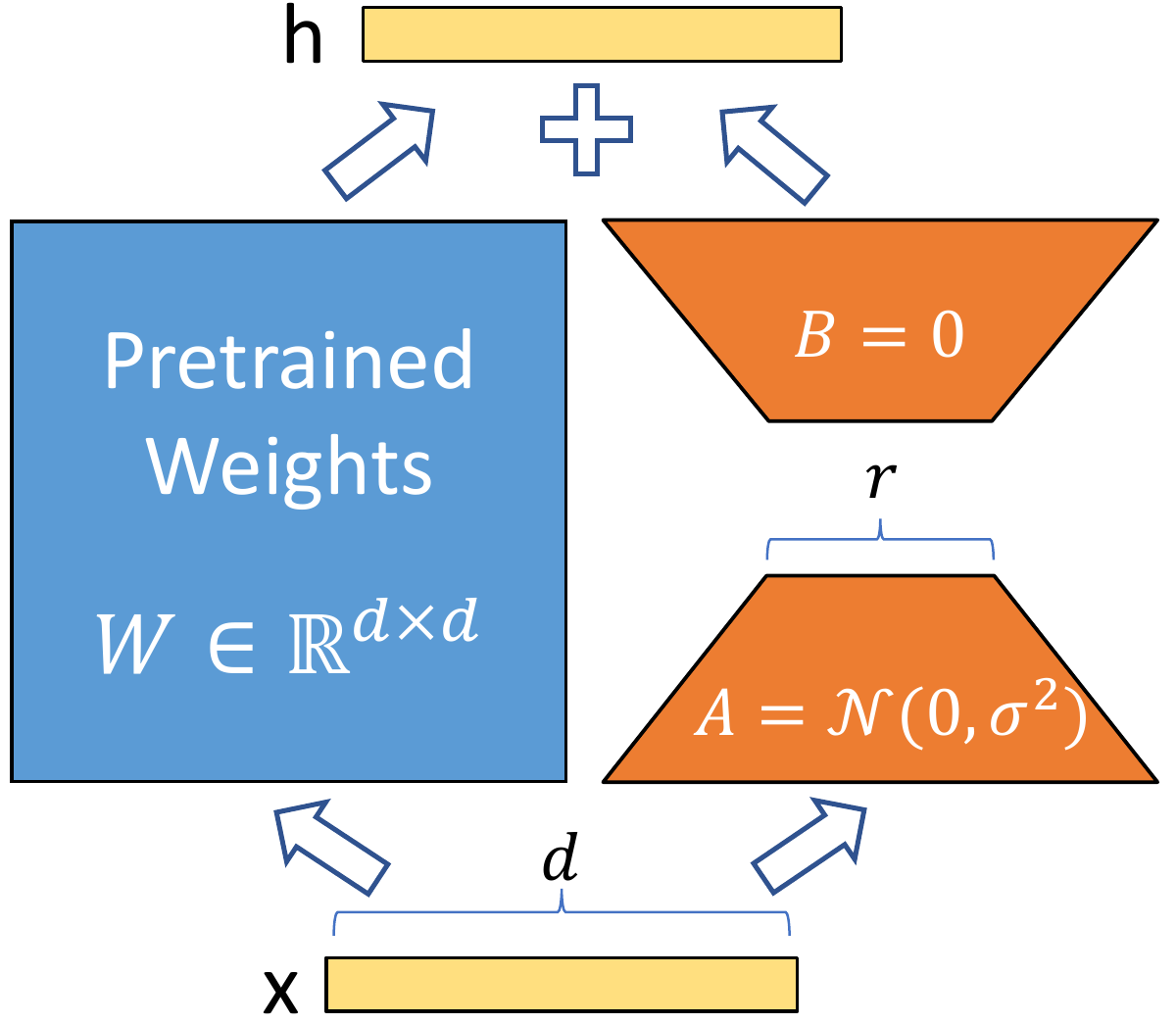
The adapted forward pass becomes:
\[h = W_0x + BAx\]The base path (W_0x) preserves the pretrained model’s general capability. The LoRA branch (BAx) learns the task-specific correction.
The original paper initializes one of the low-rank factors so that the LoRA update is zero at the start of training. That means the model initially behaves like the base checkpoint. Fine-tuning then learns a controlled residual rather than immediately perturbing the model.
Why Low Rank Can Be Enough
The low-rank assumption is not saying that the original model is low rank. It is saying that the task-specific update may lie in a much smaller subspace than the full parameter matrix.
That is a plausible assumption for many adaptation tasks. A pretrained model already contains general language, code, vision, or multimodal capability. Downstream fine-tuning often does not need to relearn syntax, common knowledge, or general representations. It needs to nudge the model toward a domain, task format, response style, or instruction distribution.
LoRA constrains that nudge. This has two consequences.
It reduces memory and storage because far fewer parameters are trainable.
It can also regularize adaptation because the model cannot freely overwrite every weight. When data is limited, this constraint can be useful. When the task genuinely requires a large structural change, the same constraint can become a bottleneck.
Where LoRA Is Inserted
LoRA is usually applied to selected linear projections inside transformer blocks. Common targets include:
- attention query and value projections;
- attention key and output projections;
- MLP up, down, and gate projections;
- sometimes all linear layers in a transformer block.
There is no universal best choice. Attention-only LoRA can be cheap and effective. Instruction tuning and chat adaptation often benefit from adding LoRA to more modules. Vision-language models, diffusion models, and robot policies may need different target modules because their bottlenecks differ.
The important point is that LoRA is a surgical update mechanism. It does not require changing the whole network, but it does require deciding where the adaptation capacity should enter.
Rank, Alpha, and Scaling
Three knobs matter in most LoRA implementations.
Rank (r) controls capacity. Small ranks such as 4, 8, or 16 are cheap. Larger ranks such as 64 or 128 can fit richer changes but increase memory and checkpoint size.
Alpha scales the LoRA branch. Many implementations use a factor like (\alpha / r), so the magnitude of the update does not accidentally change too much when the rank changes.
Dropout regularizes the LoRA path. This can help when the adaptation dataset is small or noisy.
These knobs should be tuned against the actual goal. A small classification adapter, a style-tuning adapter, a domain-specific instruction adapter, and a code-generation adapter may need different settings.
Merging and Serving
LoRA is not only a training trick. It also changes deployment.
After training, the low-rank update can be merged into the frozen weight:
\[W_{\text{merged}} = W_0 + BA\]If a deployment uses one adapter at a time, merging makes inference look like an ordinary fine-tuned model. There is no separate adapter branch at runtime.
If a deployment needs many task-specific behaviors, keeping adapters separate can be more useful. One base model can load different LoRA adapters for different domains, customers, languages, or tools. This is why LoRA became a practical format for sharing small fine-tunes.
The trade-off is batching and adapter management. If different requests in the same batch use different adapters, the serving stack must route or batch them carefully. LoRA reduces the size of the adapted model, but it does not remove all systems complexity.
QLoRA: When The Frozen Model Is Still Too Large
LoRA reduces the number of trainable parameters, but the frozen base model still has to fit in memory during training. For very large language models, that is still expensive.
QLoRA combines LoRA with low-bit storage of the frozen base model. The base model is kept in 4-bit quantized form, while gradients flow into LoRA adapters. The trainable part remains small, and the frozen part becomes much cheaper to store.
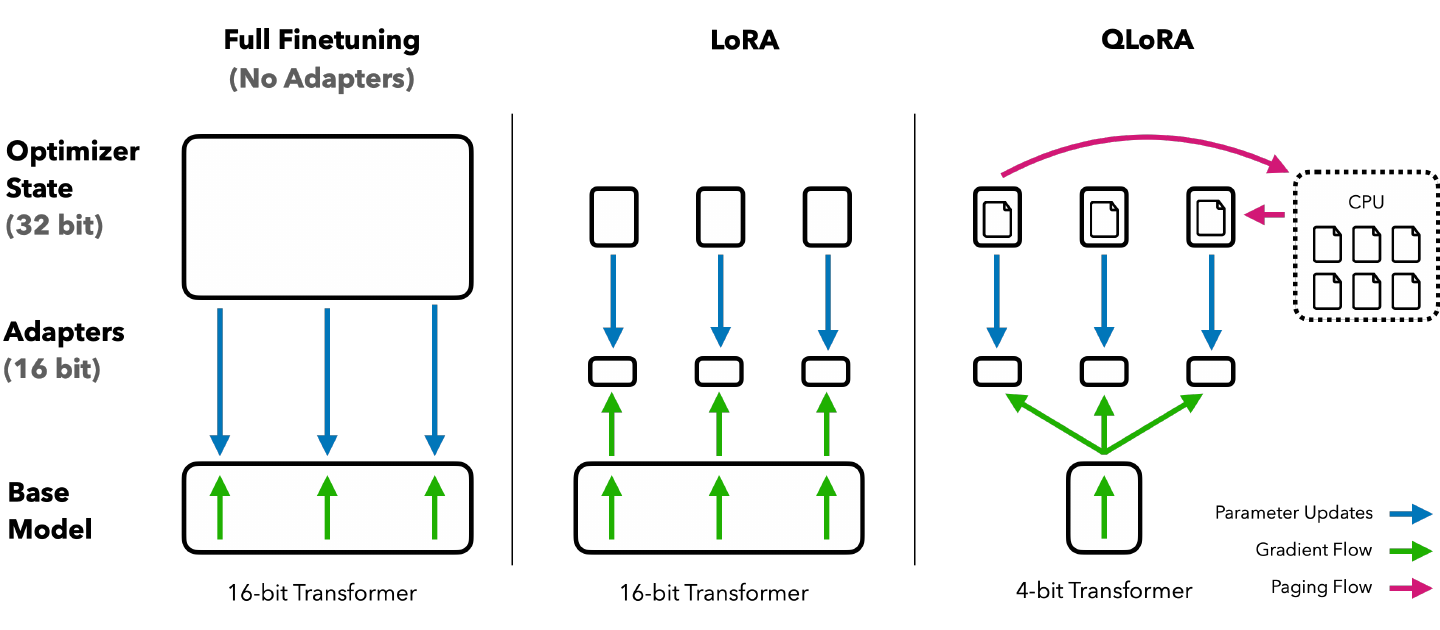
It is useful to separate the ideas:
- LoRA reduces the number of trainable parameters.
- Quantization reduces the memory needed to store the frozen base model.
- Paged optimizers and gradient checkpointing help manage memory spikes during training.
This distinction prevents a common misunderstanding. QLoRA is not “just LoRA with smaller adapters.” It is a memory system for training large models where the frozen model, activations, gradients, and optimizer states all matter.
LoRA Is Not A Knowledge Base
LoRA can teach behavior, formatting, style, domain conventions, and task-specific mappings. It can also encode some facts from the training data. But it is a poor replacement for retrieval when the main problem is fresh, private, or frequently changing knowledge.
If the goal is “answer using today’s internal documents,” LoRA is usually the wrong primary tool. Use retrieval or tool access. If the goal is “follow this organization’s answer style and cite sources consistently,” LoRA may be useful in combination with retrieval.
This distinction matters because fine-tuning and retrieval solve different problems:
| Problem | Better default |
|---|---|
| Output format, style, instruction behavior | LoRA or other fine-tuning |
| Private or changing factual knowledge | Retrieval or tool use |
| Domain-specific reasoning habits | Fine-tuning plus evaluation |
| Evidence-grounded question answering | Retrieval plus generation |
| Many small task variants | Shared base model plus adapters |
Common Failure Modes
LoRA is efficient, but it is not automatic.
Wrong data. If the adaptation data is noisy or inconsistent, LoRA will learn the noise efficiently.
Rank too small. The model may stay too close to the base behavior and fail to learn the task.
Rank too large. The adapter becomes more expensive and can overfit, especially with weak data.
Wrong target modules. Training only a few attention projections may be insufficient for some instruction or multimodal tasks.
Bad merge discipline. Repeatedly merging, stacking, or composing adapters without evaluation can produce unpredictable behavior.
Confusing adaptation with knowledge update. LoRA is not a clean database update mechanism. It is better viewed as a behavioral adaptation mechanism.
Practical Checklist
Before using LoRA, decide the following.
What behavior should change? Be specific. Style, format, reasoning pattern, tool protocol, or domain vocabulary are different targets.
Which modules should receive adapters? Start from known recipes for the model family, then evaluate attention-only versus broader target modules if performance matters.
What rank is enough? Use the smallest rank that reaches the target quality. Increasing rank is capacity, not a guarantee.
Will adapters be merged or swapped? Merging is simple for single-adapter deployment. Swapping is useful when many domains share one base model.
How will the model be evaluated? Do not rely on training loss alone. Check task success, format compliance, refusal behavior, hallucination tendency, and regression on general capabilities.
Takeaway
LoRA works because adaptation often does not require moving a model through the full parameter space. By freezing the base model and learning a low-rank residual update, it turns fine-tuning into adapter learning.
The deeper lesson is not just “use fewer parameters.” It is that large models can be treated as shared infrastructure, while task-specific behavior lives in small, auditable, replaceable modules. That is why LoRA became one of the default tools for practical model customization.