RAG: Retrieval-Augmented Generation from Indexing to Answers
Retrieval-Augmented Generation, usually shortened to RAG, is often introduced as a simple recipe: retrieve relevant documents, put them into the prompt, and let a language model answer. That description is correct, but it is too shallow. A useful RAG system is not a prompt trick. It is an evidence pipeline around a language model.
The core motivation is that language models have two kinds of memory.
Parametric memory lives inside model weights. It gives the model fluency, general knowledge, and reasoning patterns, but it is difficult to inspect or update precisely.
Non-parametric memory lives outside the model: documents, passages, databases, logs, papers, tickets, manuals, or vector indexes. It can be updated, filtered, cited, and audited.
RAG combines the two. The retriever supplies external evidence. The generator turns that evidence into an answer. The quality of the final answer depends on every step between raw documents and generated text.
This post uses figures converted from the arXiv LaTeX source of Dense Passage Retrieval, the original RAG paper, and Self-RAG.
The Original RAG Framing
The original RAG paper combined a dense retriever with a sequence-to-sequence generator. Given a query, the retriever finds the top documents from an external index. The generator then produces an answer conditioned on those documents.
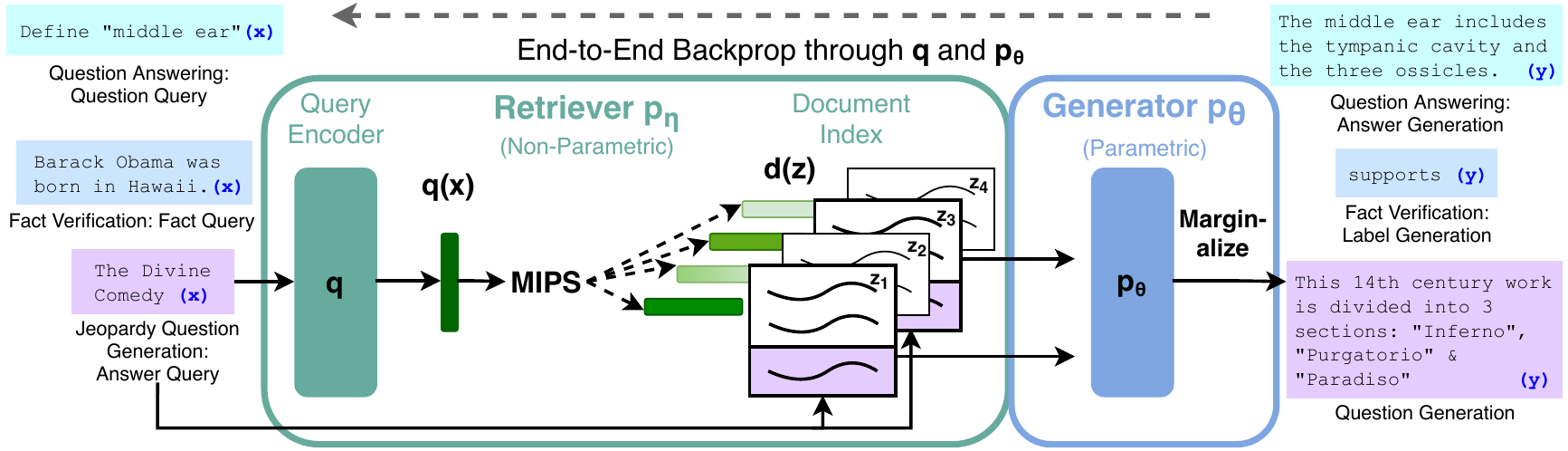
A simplified version of the RAG objective is:
\[p(y \mid x) = \sum_{z \in \text{top-}k(x)} p_\eta(z \mid x) p_\theta(y \mid x, z)\]Here, (x) is the user query, (z) is a retrieved document or passage, (p_\eta) is the retriever, and (p_\theta) is the generator. The answer is not produced from the query alone. It is produced from the query plus retrieved evidence.
That framing is still useful today, even though production RAG systems are more complex. A modern stack may include parsing, chunking, sparse retrieval, dense retrieval, metadata filters, query rewriting, reranking, citation formatting, and evaluation. But the central idea remains: generation should be grounded in retrieved evidence.
Step 1: Build The Corpus
RAG begins before the user asks a question. The first step is deciding what the system is allowed to know.
This sounds obvious, but many RAG failures start here. If the corpus is incomplete, stale, poorly parsed, or filled with duplicate documents, retrieval cannot recover. The generator can only answer from what the pipeline makes available.
Corpus design involves several choices:
- Which sources are included?
- How are old versions handled?
- Which documents are authoritative?
- What metadata is stored?
- How often is the index refreshed?
- Are permissions enforced at retrieval time?
For scientific and technical corpora, parsing quality matters. PDFs may lose section hierarchy, equations, tables, captions, or references. Web pages may include navigation noise. Code repositories need file paths, symbols, and commit context. A RAG system over poorly structured text can look functional in demos while failing on precise questions.
Step 2: Chunking Is A Modeling Decision
After documents are loaded, they are usually split into chunks. Chunking is not just preprocessing. It defines the unit of evidence that the retriever can return.
Small chunks improve retrieval specificity but may lose context. A single paragraph may contain an answer but omit the definition needed to interpret it. Large chunks preserve context but can make retrieval noisy and waste the model’s context window.
Good chunking usually respects document structure:
- section headings and subsections;
- paragraph boundaries;
- tables and captions;
- code blocks and function definitions;
- paper abstracts, methods, experiments, and conclusions;
- metadata such as title, date, author, source, and version.
The chunk should be large enough to be meaningful and small enough to retrieve precisely. There is no universal chunk size.
Step 3: Retrieval Is Not One Method
Retrieval can be sparse, dense, or hybrid.
Sparse retrieval uses exact lexical signals. BM25 is strong when names, identifiers, equations, API symbols, or rare terms matter.
Dense retrieval maps queries and passages into vector space. It is useful when the query and document use different words but share meaning.
Hybrid retrieval combines both. This is often the most practical default because real questions contain both semantic intent and exact constraints.
Dense Passage Retrieval was an important step because it showed that learned dense retrievers could outperform sparse retrieval for open-domain question answering when trained with question-passage supervision.
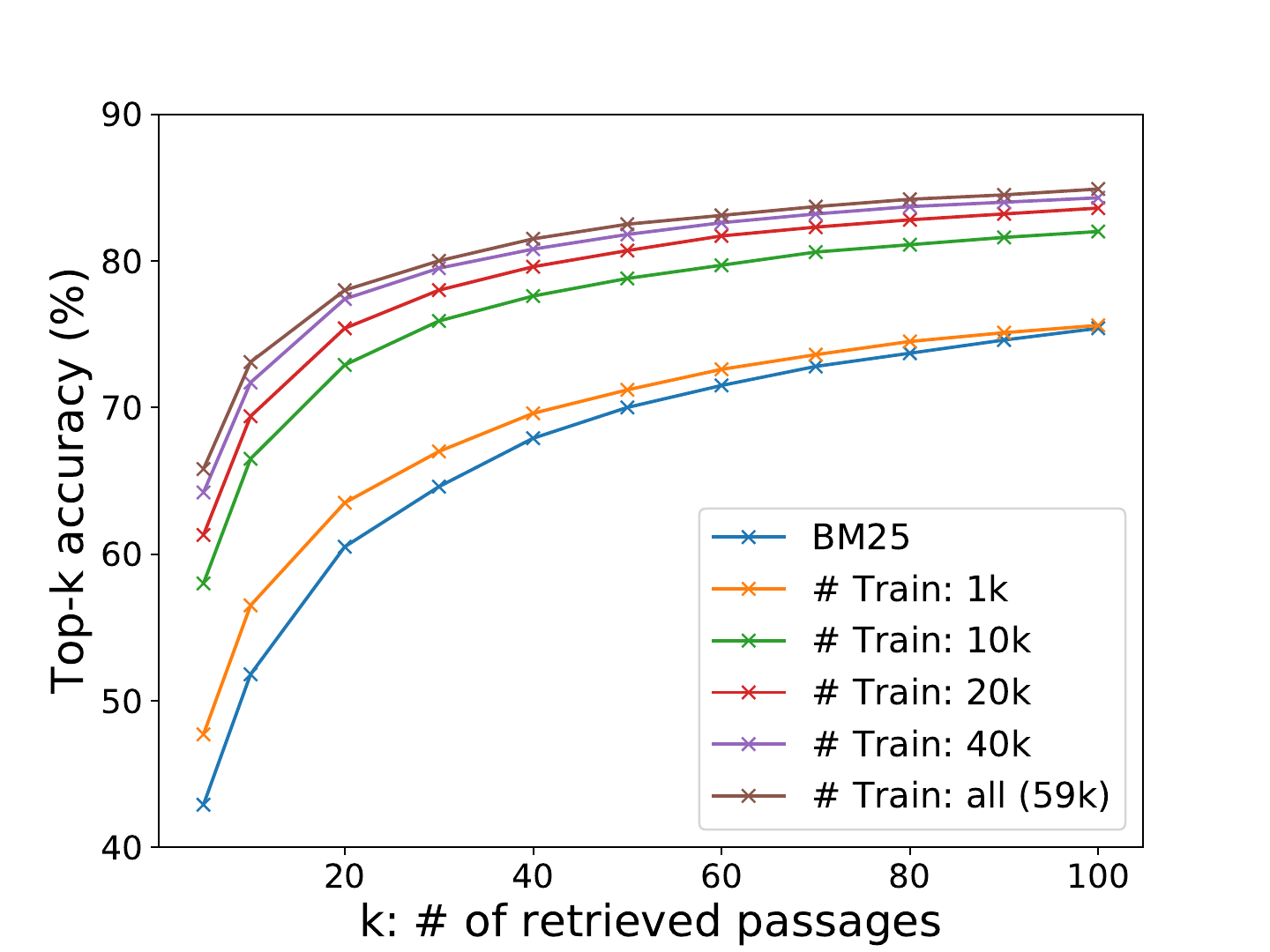
Dense retrieval is powerful, but it is not automatically better. It can retrieve semantically similar but constraint-violating passages. Sparse retrieval can be better for exact names, numbers, file paths, or code symbols. A robust RAG system often uses both, then reranks.
Step 4: Reranking Separates Recall From Precision
The first retriever should usually optimize recall. It should avoid missing relevant evidence. But the generator should not receive every vaguely related chunk. Too much irrelevant context can distract the model, increase latency, and push useful evidence out of the context window.
Reranking solves this by splitting retrieval into two stages.
First, a cheap retriever returns a candidate set. This might be top 50 or top 100 chunks from dense, sparse, or hybrid retrieval.
Second, a stronger reranker scores candidates more carefully. This can be a cross-encoder, a late-interaction model, or an LLM-based relevance judge.
This separation matters because final answer quality is often limited by the context handed to the generator. A strong generator cannot cite evidence it never receives. It can also be misled by irrelevant evidence it should not have received.
Step 5: Generation Is Evidence Use, Not Just Fluency
Once the system selects context, the generator must answer using it. The prompt should make the evidence contract explicit:
- use the retrieved context when it is relevant;
- cite sources when required;
- distinguish evidence from inference;
- say when the context is insufficient;
- avoid using unsupported parametric memory for source-grounded claims.
This is where many RAG demos look better than they are. The answer may be fluent, but fluency is not grounding. A good RAG answer should be traceable. A human should be able to inspect the retrieved passages and see why the answer was produced.
The generator may still need its parametric memory. Retrieved evidence can be incomplete, terse, or fragmented. The model must synthesize, summarize, compare, and explain. RAG is not “copy the nearest paragraph.” It is evidence-conditioned generation.
Step 6: Decide When To Retrieve
The earliest RAG systems retrieved a fixed number of documents for every input. Modern systems often need more control.
Some questions are answerable without retrieval. Some need one precise document. Some need multiple sources. Some need an external database or tool call rather than document retrieval. Some require retrieval at multiple steps because the answer depends on a chain of facts.
Self-RAG makes this issue explicit by training a model to retrieve, critique, and generate with reflection tokens. The broader lesson is that retrieval should be a decision, not always a fixed preprocessing step.
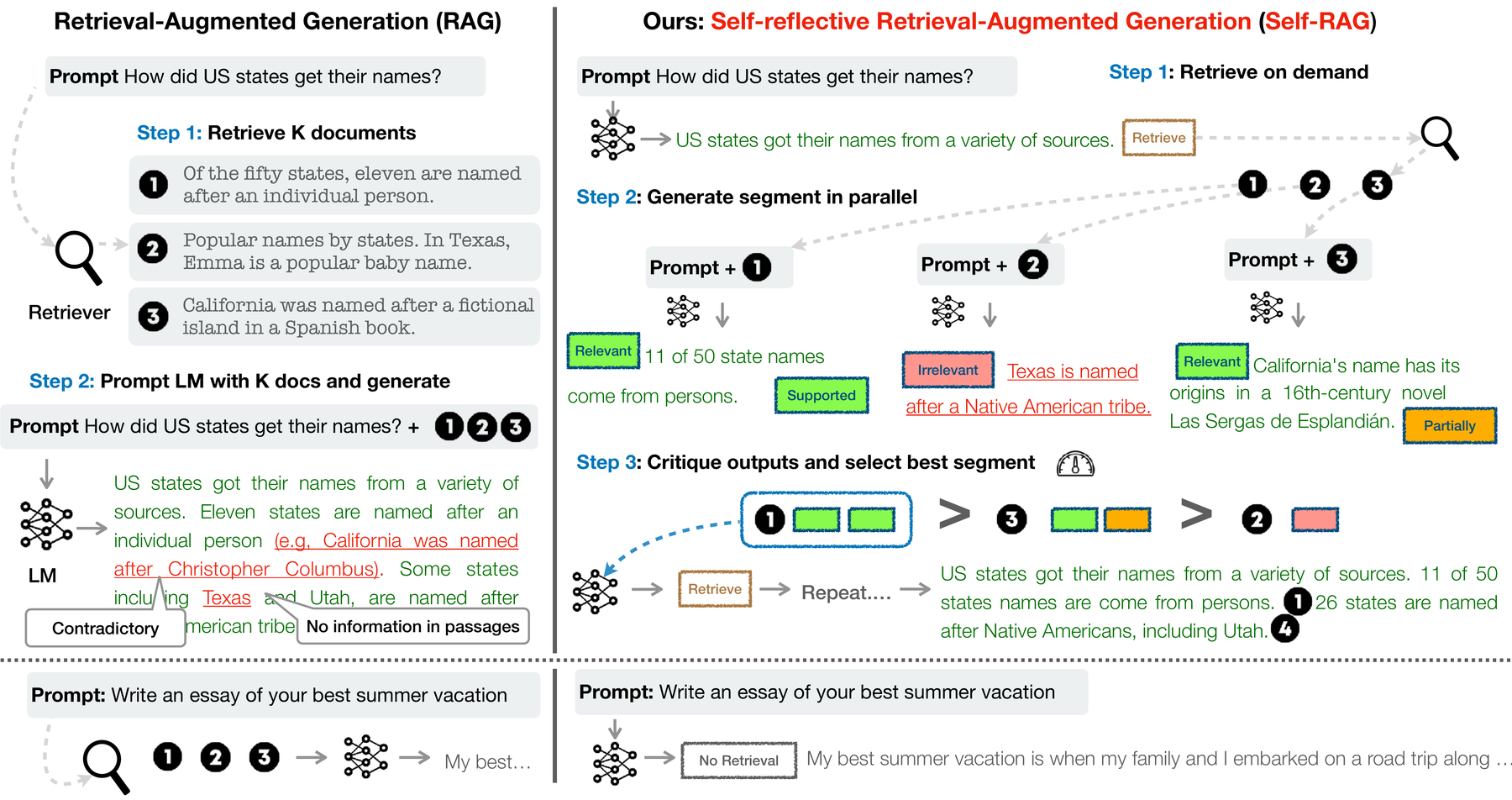
This idea becomes important for long-form answers. The system may need to retrieve evidence for one section, write a partial answer, detect a missing claim, retrieve again, and revise. A single top-(k) retrieval call at the beginning may be insufficient.
Where RAG Fails
RAG can fail at every layer of the pipeline.
Corpus failure. The right document is missing, stale, duplicated, or hidden behind permissions.
Parsing failure. The answer exists in a table, caption, equation, or scanned PDF region that the parser did not extract correctly.
Chunking failure. The answer and its definition are split into different chunks, so retrieval returns incomplete evidence.
Embedding failure. The dense retriever retrieves semantically related text that violates an exact constraint.
Ranking failure. The relevant passage is in the candidate set but not in the final context.
Context failure. Too many chunks are passed to the model, and irrelevant text distracts generation.
Generation failure. The model ignores the evidence, overgeneralizes, or answers from parametric memory.
Citation failure. The answer is correct but cites the wrong source, making it hard to audit.
This is why “we added RAG” is not a complete technical description. The actual system is the ingestion, indexing, retrieval, reranking, prompting, generation, and evaluation loop.
Evaluation Should Be Decomposed
A RAG system should not be evaluated only by final answer quality. Final quality is important, but it hides the cause of failure.
Useful retrieval metrics include:
- recall@k: did the retrieved set contain the needed evidence?
- precision@k: how much retrieved context was actually useful?
- mean reciprocal rank: how high was the first relevant result?
- coverage across query types: exact names, synonyms, long questions, ambiguous questions, and multi-hop questions.
Useful generation metrics include:
- answer correctness;
- faithfulness to retrieved evidence;
- citation accuracy;
- abstention when evidence is insufficient;
- conciseness and usefulness.
Operational metrics matter too:
- indexing time;
- query latency;
- reranking cost;
- context length;
- failure under stale or adversarial documents.
A RAG system that is accurate but too slow may not be deployable. A RAG system that is fast but unfaithful may be worse than no retrieval because it creates false confidence.
RAG Versus Fine-Tuning
RAG and fine-tuning are often compared, but they solve different problems.
Use RAG when the main problem is external knowledge: private documents, recent facts, source-grounded answers, legal or scientific evidence, or auditability.
Use fine-tuning when the main problem is behavior: answer style, output format, task protocol, tool use, domain-specific reasoning habits, or consistent refusal behavior.
Strong systems often use both. Fine-tuning teaches the model how to behave. RAG supplies the evidence needed for each specific query.
For example, a medical assistant might be fine-tuned to follow a conservative answer format, but use RAG to cite the latest guidelines. A coding assistant might be fine-tuned to produce concise patches, but retrieve project-specific files and issue history. A scientific assistant might be fine-tuned to write structured summaries, but retrieve papers, tables, and figures for evidence.
Practical Design Checklist
A serious RAG system needs decisions in at least eight places.
Corpus. Which sources are trusted, current, and permissioned?
Parsing. Are tables, equations, code, images, and captions preserved?
Chunking. Is the chunk an evidence unit that a model can use?
Indexing. Are dense, sparse, and metadata indexes updated reliably?
Retrieval. Does the first stage optimize recall without flooding the context?
Reranking. Is there a precision layer before generation?
Prompting. Does the model know how to use evidence and when to abstain?
Evaluation. Can failures be attributed to retrieval, context, generation, or citation?
Skipping any of these can produce a system that works on demos but fails on real questions.
Takeaway
RAG is best understood as a knowledge interface around a language model. It does not magically prevent hallucination. It gives the model access to inspectable evidence and creates a path for answers to be grounded, cited, updated, and audited.
The useful mental model is:
\[\text{documents} \rightarrow \text{chunks} \rightarrow \text{index} \rightarrow \text{retrieval} \rightarrow \text{reranking} \rightarrow \text{context} \rightarrow \text{answer}\]Every arrow is a design choice. The final answer is only as strong as the weakest step in that chain.
Further Reading
- Dense Passage Retrieval for Open-Domain Question Answering
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- REALM: Retrieval-Augmented Language Model Pre-Training
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- RAGAS: Automated Evaluation of Retrieval Augmented Generation
- Faiss documentation