LIBERO: A Practical Guide to Language-Conditioned Manipulation Benchmarks
LIBERO is a benchmark for lifelong robot learning from language-conditioned manipulation tasks. The paper is useful because it separates several kinds of generalization pressure instead of treating tabletop manipulation as one monolithic success-rate number.
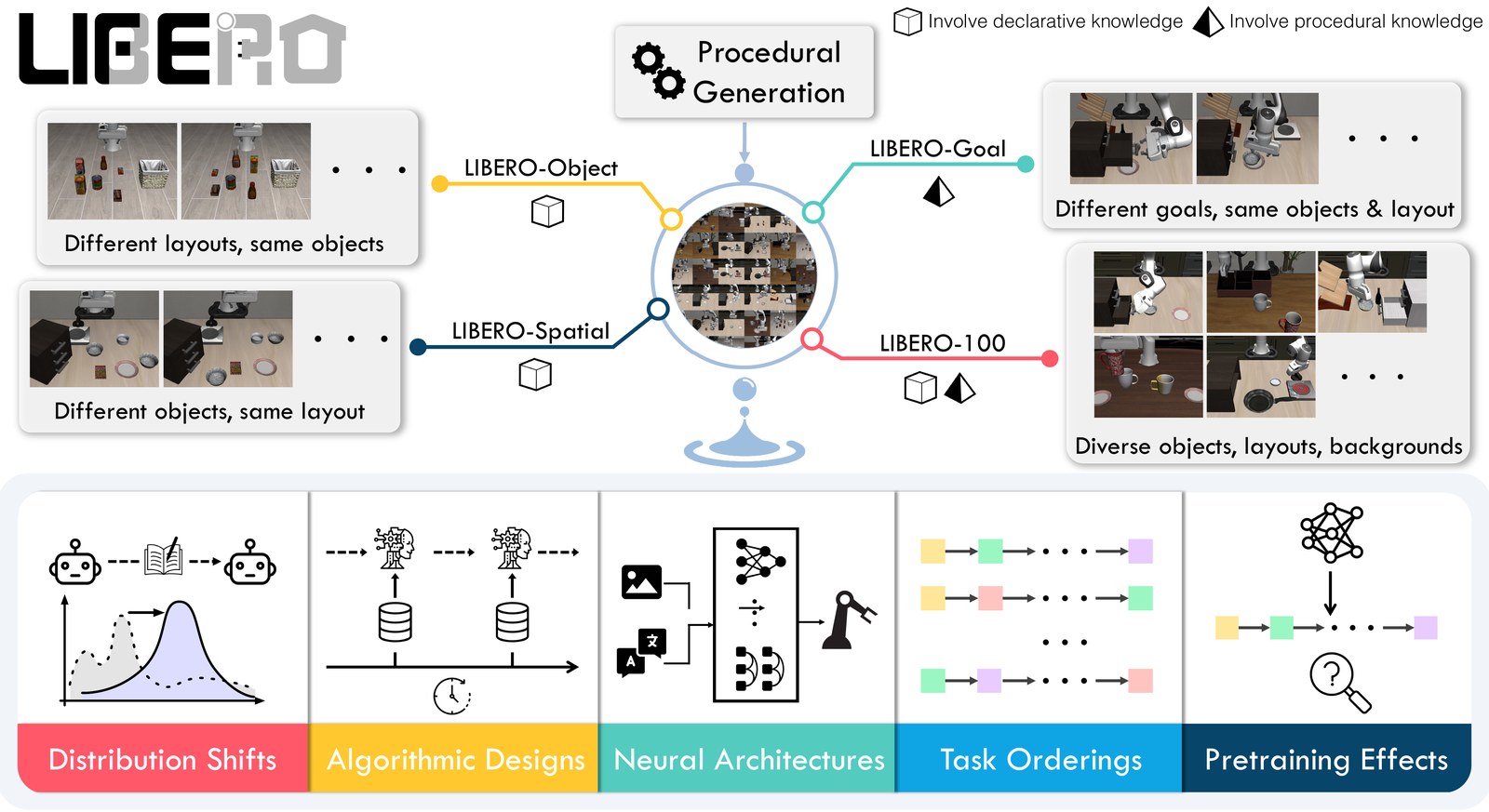
What the Paper Contributes
The core design is a set of procedurally generated task suites for language-conditioned manipulation. The paper highlights four major suites:
| Suite | What it stresses |
|---|---|
| LIBERO-Spatial | Generalization over spatial relations and object placements |
| LIBERO-Object | Generalization over object identity and visual variation |
| LIBERO-Goal | Generalization over goal predicates |
| LIBERO-100 | A larger task set for broader lifelong-learning evaluation |
For current VLA evaluation, I would normally report the four task groups as Spatial, Object, Goal, and Long. The Long group is often represented by LIBERO-10, while LIBERO-90/100 are more useful when the question involves broader multitask pretraining or lifelong learning. This distinction matters because a method can look strong on object changes but still fail on goal-predicate transfer or long-horizon execution.
This structure is why LIBERO is a good benchmark for vision-language-action models. A policy must connect language, perception, action, and a task-level success predicate, while the evaluation can isolate which kind of transfer is breaking.
How to Use It
Use LIBERO when the claim involves language-conditioned manipulation, lifelong learning, VLA fine-tuning, or controlled transfer across objects, goals, and layouts. A minimal exploration usually starts by loading a suite and inspecting the task language:
from libero.libero import benchmark
suite = benchmark.get_benchmark_dict()["libero_10"]()
task = suite.get_task(0)
print(task.language)
For a real experiment, also record the suite name, observation mode, camera preprocessing, action scaling, initial-state protocol, and success predicate. Those details matter because the benchmark is often used to compare small changes in policy architecture or test-time strategy.
Practical Usage Notes
The most important habit is to treat the suite name as part of the result, not as background metadata. A table that says “LIBERO success rate” without saying Spatial, Object, Goal, Long, LIBERO-10, or LIBERO-90 is usually not interpretable.
In practice, the most useful checklist is:
- record suite, task ID, language instruction, seed, camera names, and image resolution;
- verify the initial-state protocol before comparing two policies;
- export rollout videos with the same camera convention used by the evaluator;
- report success rate together with timeouts, average horizon, and action throughput;
- separate language-grounding failures from contact-control failures when inspecting rollouts.
For VLA work, I would start with a small suite-level smoke test before running a full benchmark. If a policy cannot reliably reset, render, and execute a few LIBERO-10 rollouts, a larger Spatial/Object/Goal/Long table will mainly hide pipeline errors behind aggregate numbers.
What to Look For
The paper frames LIBERO as more than a task collection. It is a way to ask whether a method can keep learning across a stream of related manipulation problems. When reading a LIBERO result, check whether the method improves uniformly or only on one suite. For example, an object-centric improvement may not help with goal-predicate transfer.
It is also worth inspecting rollout videos. A single failure rate can hide different problems: language grounding, perception, object contact, action drift, or a strict predicate that does not match visual progress.
Limits
LIBERO is simulated and tabletop-oriented. Strong performance does not by itself prove real-robot reliability, household interaction, multi-arm coordination, or robust deployment under uncontrolled scene changes.
Paper Source
This note was revised from the paper and its LaTeX source package: LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning.