CALVIN: Long-Horizon Language-Conditioned Manipulation
CALVIN is a benchmark for long-horizon, language-conditioned manipulation. Its main contribution is the evaluation setup: a policy should not only solve one short instruction, but continue through a chain of subtasks using language and multimodal observations.
What the Paper Contributes
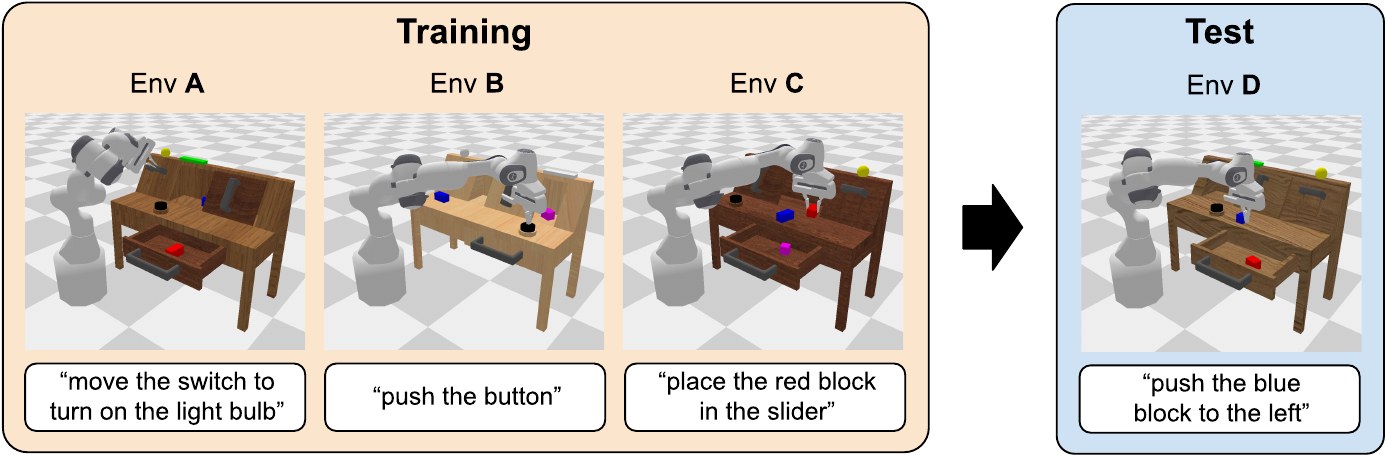
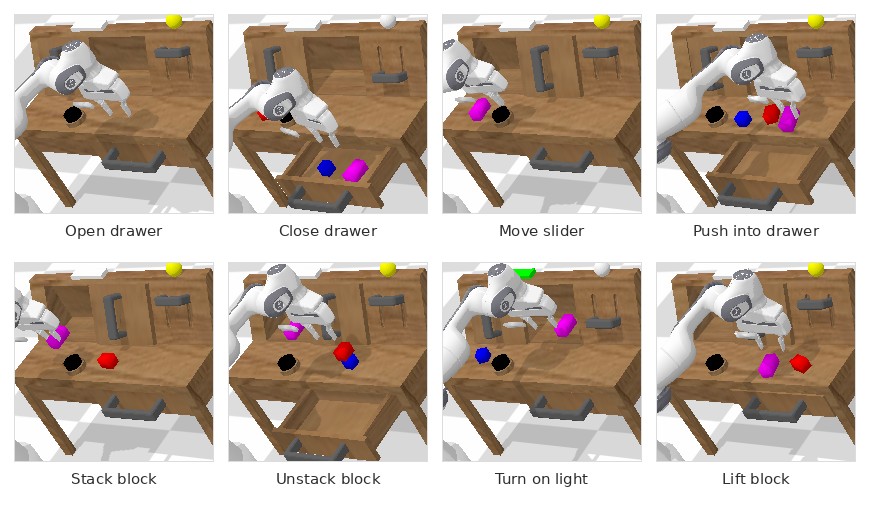
The paper collects about twenty-four hours of teleoperated play data across four environments. It then builds language-conditioned tasks by combining recorded state information with hundreds of natural-language instructions. The benchmark contains 34 task types and evaluates policies on chains of five sequential instructions.
The hardest split is especially useful: train on three environments and test in an unseen environment. This makes CALVIN a stronger test of generalization than a single-scene imitation-learning setup.
What It Tests
CALVIN is useful for:
- long-horizon instruction following;
- policy memory and history conditioning;
- task-oracle evaluation over composed subtasks;
- static-camera, gripper-camera, and robot-state conditioning;
- VLA-style policies that need action chunks, closed-loop correction, or progress monitoring.
The important metric is not just whether the first instruction succeeds. CALVIN asks how far the policy gets through a sequence before compounding errors stop it.
How to Use It
The practical workflow is:
choose split -> load language instruction -> run policy rollout -> score with task oracle
For early debugging, load a small validation episode and render both the static and gripper views. Before training or evaluating a large model, verify observation keys, camera resolution, language strings, robot-state normalization, and action scaling.
Practical Usage Notes
The guide-level lesson is that CALVIN should be debugged visually before it is debugged statistically. A sequence score can collapse because of a camera mismatch, a wrong robot-state normalization, an action-scale error, or an oracle mismatch. Those problems look similar in a table but very different in videos.
Useful checks before a serious run:
- inspect both the static and gripper camera streams;
- verify the task oracle on a few known successful and failed episodes;
- report the split, especially whether evaluation is seen-environment or unseen-environment;
- include per-subtask success instead of only average completed instructions;
- save failure clips for the first failed subtask in each sequence.
For action-chunking policies, also state whether the model emits one 7D action at a time or a longer action chunk. Changing that interface can change recovery behavior even when the model architecture is unchanged.
What To Watch Out For
CALVIN is sensitive to preprocessing details. A model can fail because of camera convention mismatch or action normalization, even when the high-level method is reasonable.
Also avoid reporting only average sequence length. Per-subtask success and rollout videos often reveal whether the bottleneck is drawer motion, slider control, object placement, or recovery after an imperfect intermediate state.
Limits
CALVIN is still a simulated benchmark. It is excellent for long-horizon language-conditioned control, but it does not replace real-robot deployment or household-scale scene diversity.
Paper Source
This note was revised from the paper and its LaTeX source package: CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks.