MetaWorld: A Compact Benchmark for Multi-Task Tabletop Manipulation
MetaWorld is a MuJoCo benchmark for multi-task and meta-reinforcement learning in robotic manipulation. The paper is useful because it provides 50 distinct manipulation task families under a shared robot interface, making task diversity the main object of study.

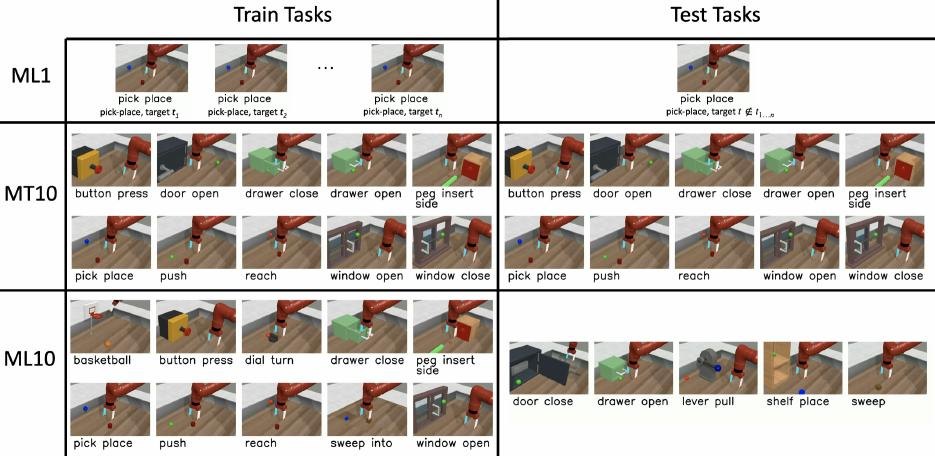
What the Paper Contributes
MetaWorld was designed to move meta-RL and multi-task RL beyond narrow task families. Instead of only varying a goal location inside one environment, it includes qualitatively different skills such as reaching, pushing, pick-place, opening doors, operating drawers, pressing buttons, inserting pegs, and opening windows.
The common evaluation modes are:
| Split | Purpose |
|---|---|
| ML1 | Few-shot adaptation within one task family |
| MT10 | Multi-task learning over 10 task families |
| MT50 | Multi-task learning over all 50 task families |
| ML10 | Meta-learning with held-out test tasks |
| ML45 | The harder meta-learning setting using 45 training tasks and held-out tasks |
The paper’s key point is that a method should not only learn a single manipulation skill. It should reuse structure across many related but distinct manipulation problems.
How to Use It
import metaworld
benchmark = metaworld.MT1("door-lock-v3")
env = benchmark.train_classes["door-lock-v3"]()
task = benchmark.train_tasks[0]
env.set_task(task)
obs = env.reset()
obs, reward, done, truncated, info = env.step(env.action_space.sample())
env.close()
For fair comparison, report the benchmark split, task list, seed, horizon, success definition, and whether evaluation uses state observations or rendered images.
Practical Usage Notes
“MetaWorld” is not a single setting. MT and ML splits answer different questions, and a custom four-task subset should not be compared as if it were MT50 or ML45.
For a clean report, include:
- exact task family names and version suffixes;
- MT or ML split, plus whether the run is a custom subset;
- observation type, action normalization, horizon, seed count, and success definition;
- per-task success in addition to the averaged score;
- whether the experiment is about multitask learning, meta-learning, or task/client heterogeneity.
MetaWorld is also useful for federated or distributed-learning prototypes because task heterogeneity is controllable. But the claim should stay scoped: strong MetaWorld performance does not establish language grounding, photorealistic perception, or real-robot deployment.
When To Use It
Use MetaWorld when the experiment needs a clean multi-task manipulation testbed, task/client heterogeneity, policy adaptation, or quick simulation feedback.
It is a good middle ground between very small control tasks such as PushT and larger scene-rich benchmarks such as RoboCasa.
Limits
MetaWorld is not a language-rich VLA benchmark by default, and it is not a real-world dataset. It also does not capture the visual complexity of household scenes. Use it for controlled manipulation learning, not as the only proof of embodied intelligence.
Paper Source
This note was revised from the paper and its LaTeX source package: Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning.