AgiBot World Colosseo: Data, Models, Benchmarks, and Ecosystem
AgiBot World Colosseo is a large-scale embodied manipulation platform. The paper is useful because it frames the release as a combined ecosystem: data, models, benchmarks, robot platform, and code are meant to support generalist robot learning rather than a single isolated environment.
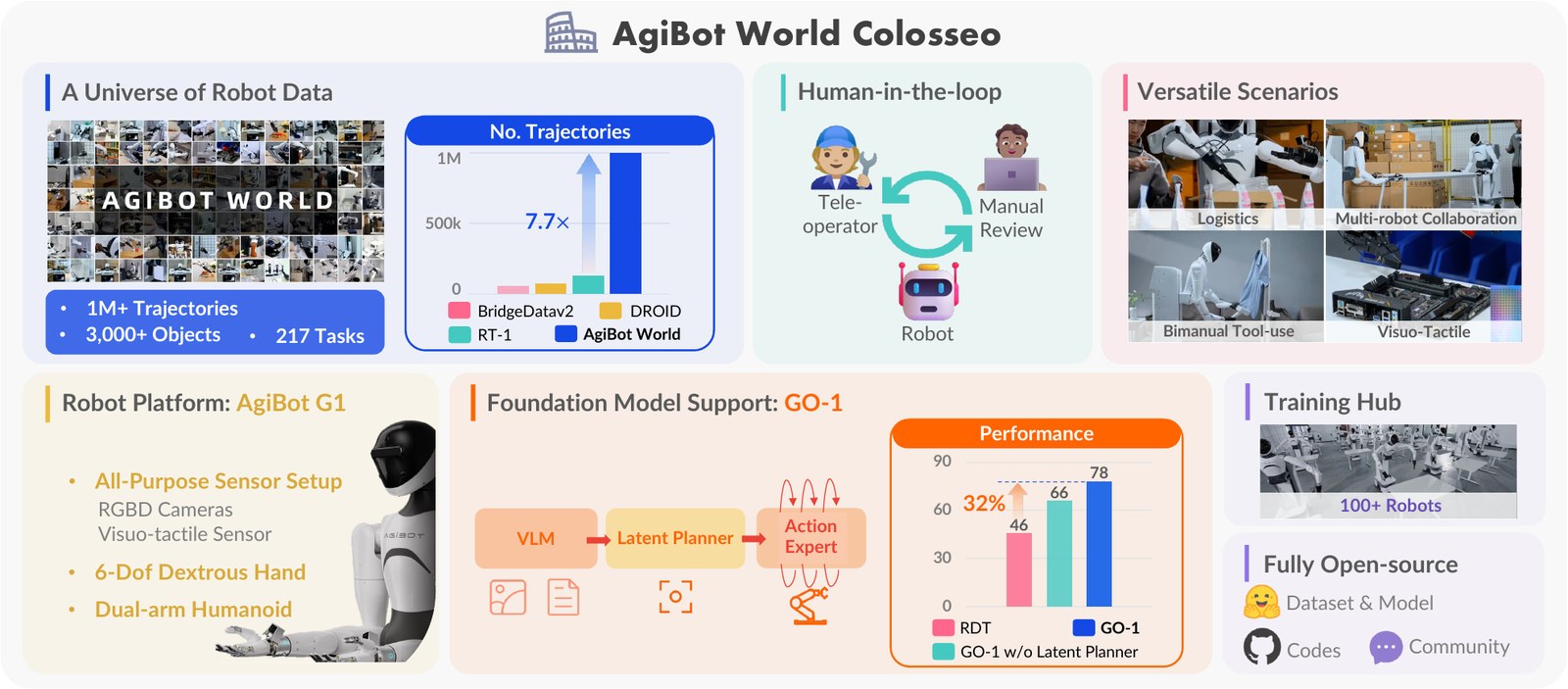
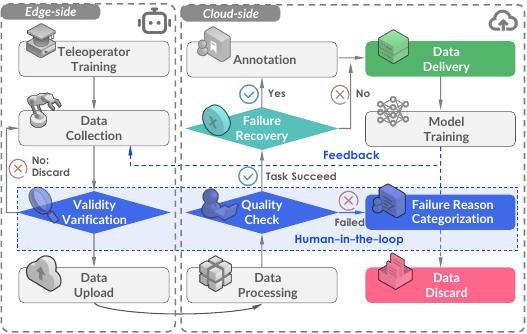
What the Paper Contributes
The paper introduces AgiBot World Colosseo as an open-sourced manipulation platform with a deployed suite of 100 dual-arm humanoid robots. It also presents a generalist policy, ViLLA, which uses a latent action planner to bridge vision-language inputs and dexterous robotic action.
The release should be read as several connected pieces:
| Asset type | Best use |
|---|---|
| Data | Scaling robot manipulation learning and analysis |
| Models | Studying generalist policies and latent-action planning |
| Benchmarks | Comparing manipulation and embodied-policy methods |
| Ecosystem | Reusing code, assets, and platform conventions |
This separation matters. A world-model dataset is not automatically an action-policy dataset. A simulator asset pack is not a benchmark by itself.
How to Use It
The practical workflow is:
choose asset track -> inspect expected input/output -> run baseline smoke -> adapt model or evaluator
For model work, first reproduce the expected data format and baseline I/O. For benchmark work, state which track, metric, and subset are used. For simulator or ecosystem reuse, keep the claim scoped to the asset actually used.
Practical Usage Notes
The ecosystem should be split into tracks: world-model data, VLA/action data, simulator assets, and baseline repositories. Mixing those tracks makes a result hard to understand. A model trained on one track is not automatically evaluated on another.
For each experiment, write down:
- which asset track is used: world model, VLA/action, simulator asset, benchmark, or baseline code;
- expected input and output format before modifying the model;
- subset size, modality, and whether depth or only RGB is available;
- baseline reproduction status before adding a new method;
- the exact benchmark metric or downstream claim supported by that track.
This is especially important for large ecosystem releases. They are valuable because many resources are aligned, but that does not mean every resource carries the same kind of evidence. A simulator asset pack supports environment construction; a world-model dataset supports prediction or planning studies; a VLA dataset supports action learning.
When To Use It
Use AgiBot World resources when the research question involves robot world models, future video prediction, planning with predicted observations, VLA action learning, dexterous manipulation, or simulation asset reuse.
It is especially useful when a project needs more than a single environment. Data, model code, benchmark definitions, and platform conventions can be aligned around the same release.
What To Be Careful About
Do not collapse all assets into one claim. If a result uses a model benchmark, say that. If it uses data for pretraining, say that. If it only reuses simulator assets or code, do not imply full benchmark evaluation.
This distinction keeps the benchmark story honest and makes results easier to reproduce.
Paper Source
This note was revised from the paper and its LaTeX source package: AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems. The paper lists the project website at https://agibot-world.com/ and code at OpenDriveLab/AgiBot-World.