KV Cache: The Hidden Memory Bottleneck in LLM Serving
When people talk about serving large language models, the first memory number they usually mention is model size. A 7B model in FP16 needs roughly 14 GB for weights. A 70B model needs far more. That is real, but it is not the whole serving problem.
In autoregressive generation, another memory object grows with every request: the key-value cache, usually called the KV cache. The cache stores attention keys and values from previous tokens so that the model does not recompute the full prefix every time it generates a new token. This makes decoding much faster, but it also turns memory management into a central systems problem.
The surprising part is that the KV cache can become the bottleneck even when model weights fit comfortably. Throughput is often limited not by arithmetic alone, but by how many active requests and cached tokens can fit in GPU memory at once.
Why KV Cache Exists
A transformer generates text one token at a time. To predict the next token, each layer attends to the previous tokens in the sequence. Without caching, the model would repeatedly recompute the key and value vectors for the same prefix at every decoding step.
KV caching avoids that waste. During the prompt phase, the model computes keys and values for the prompt tokens and stores them. During generation, each new token adds one more key and value vector to the cache. Future tokens can attend to the stored vectors directly.
This changes the cost structure of serving.
The prompt phase can use large matrix-matrix operations and is relatively GPU-friendly. The generation phase is sequential, uses small per-token operations, and repeatedly reads from the KV cache. The longer the context and the more concurrent requests, the larger the cache becomes.
Why It Becomes a Bottleneck
The KV cache grows with several factors:
- number of layers;
- number of attention heads or KV heads;
- head dimension;
- precision;
- sequence length;
- number of active sequences.
For a single token, the cache stores both a key and a value for each relevant layer. A rough memory shape is:
\[\text{KV memory} \propto 2 \times L \times H_{kv} \times D \times T \times B\]Here, $L$ is the number of layers, $H_{kv}$ is the number of key-value heads, $D$ is the head dimension, $T$ is the sequence length, and $B$ is the number of active sequences. The factor of two comes from storing both keys and values.
This means long-context serving and high-concurrency serving stress the same resource: GPU memory for cached attention state.
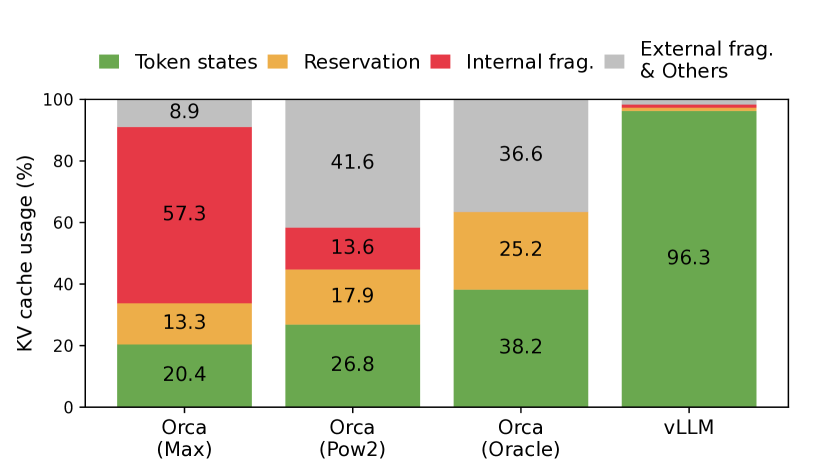
The Allocation Problem
The hard part is not only that KV cache is large. It is also dynamic.
A server usually does not know in advance how long a request will generate. Some users send short prompts and stop after a sentence. Others send long conversations and request long outputs. Requests also arrive and finish at different times.
If the serving system reserves the maximum possible cache length for every request, memory is wasted for short outputs. If it tries to compact memory aggressively, it may introduce expensive copying. If it stores every request in one contiguous region, fragmentation becomes painful as requests grow and finish.
This is similar to an old operating systems problem: processes need memory, their memory grows and shrinks, and contiguous allocation wastes space. PagedAttention applies a similar idea to KV cache.
PagedAttention in One Picture
PagedAttention breaks the KV cache into fixed-size blocks. A request sees a logical sequence of KV blocks, but those logical blocks can map to non-contiguous physical blocks in GPU memory.
This design has three useful properties.
First, memory can be allocated on demand. The system does not need to reserve the maximum sequence length upfront.
Second, fixed-size blocks reduce external fragmentation. Freed blocks can be reused by other requests.
Third, block-level mapping makes sharing possible. Multiple sequences can share prefix blocks, and copy-on-write can be used when they diverge.
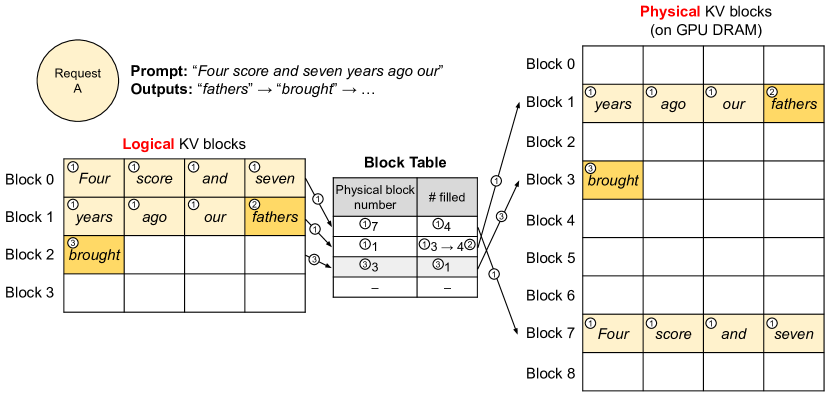
The analogy is direct:
- requests are like processes;
- tokens are like bytes;
- KV blocks are like pages;
- the block table is like a page table;
- physical KV blocks are GPU memory pages.
The details are GPU-specific, but the intuition is familiar: separate the logical view from the physical layout.
Why Continuous Batching Needs Good Cache Management
LLM services usually want to batch many active requests together. Batching amortizes model weight access and improves GPU utilization. However, autoregressive decoding makes batching awkward because requests have different lengths and finish at different times.
Modern serving systems use iteration-level or continuous batching. After each decoding step, completed requests can leave the batch and new requests can enter. This improves utilization, but it also means the KV cache allocator must handle a constantly changing set of active sequences.
If the allocator wastes cache space, the batch cannot grow. If the batch cannot grow, throughput suffers. In high-throughput serving, KV cache management directly affects how many requests can be served at once.
This is why PagedAttention was not only an attention kernel idea. It was part of a serving system design in vLLM, including scheduling, block management, and cache sharing.
Prefix Sharing and Copy-on-Write
KV cache sharing matters when several sequences share the same prefix.
This happens in beam search, parallel sampling, multi-output generation, chat templates, and workloads with shared system prompts. Without sharing, each branch may store a duplicate copy of the same prefix KV cache. With block-level sharing, multiple sequences can point to the same physical blocks.
When a sequence needs to write into a shared block, the system can allocate a new block and copy only that block. This is the same copy-on-write idea used in operating systems.
The win depends on workload. Shared prompts, long prefixes, beam search, and parallel sampling benefit more than independent short prompts.
What KV Cache Optimizations Do Not Solve
Paged KV cache management helps memory utilization, but it does not remove every inference bottleneck.
The model still has to read weights, read cached keys and values, run attention, compute logits, sample tokens, and move data through the system. The generation loop is still sequential. For very small batch sizes, latency may be dominated by different overheads. For very large models, tensor parallelism and interconnect bandwidth matter. For very long contexts, attention itself can become expensive even if memory is well managed.
KV cache also creates a quality and systems tradeoff. Longer context can improve capabilities, but it increases memory pressure and can reduce concurrency. Compression, eviction, quantized KV cache, grouped-query attention, and state-space or linear-attention alternatives all attack related parts of the same problem.
Practical Mental Model
A useful way to reason about LLM serving is to separate three memory pools.
Weights are mostly fixed after the model is loaded. They determine the baseline memory footprint.
Activations and temporary buffers fluctuate during computation. They depend on kernels, batch shape, and implementation details.
KV cache grows with active tokens. It depends on traffic, output lengths, context lengths, decoding algorithms, and scheduling.
For offline single-request inference, model weights may dominate. For online high-concurrency serving, KV cache can become the limiter. For long-context chat, the cache can grow fast even with modest request rates.
Takeaway
KV caching is the reason autoregressive decoding is practical, but it is also one of the main reasons LLM serving is a systems problem. The cache grows with sequence length and concurrency, and inefficient allocation can waste enough memory to reduce throughput dramatically.
PagedAttention is important because it treats KV cache as a dynamic memory management problem. By splitting cache into blocks and mapping logical blocks to physical GPU memory, serving systems can batch more requests, share prefixes, and reduce fragmentation.
The simple takeaway is: fitting the model weights is only the first step. Efficient serving also requires fitting the conversation history of many users at the same time.
Further Reading
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- vLLM Paged Attention design document
- Orca: A Distributed Serving System for Transformer-Based Generative Models
- FlashAttention: Fast and Memory-Efficient Exact Attention
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention