Robot Data at Scale: From Open X-Embodiment to DROID
Robot learning has a data problem that is easy to underestimate. A language model can consume text from the web. A vision model can learn from images and captions. A robot policy needs trajectories: observations, actions, timing, embodiment details, and the messy physical consequences of contact.
This makes robot data expensive. Every demonstration requires hardware, calibration, safety procedures, human effort, and a physical scene. Worse, a trajectory collected on one robot is not automatically useful for another robot. The camera placement, gripper, action space, controller, and workspace can all change.
The recent push toward robot foundation models is therefore also a push toward robot data infrastructure. Two useful reference points are Open X-Embodiment, which aggregates many existing robot datasets into a shared format, and DROID, which focuses on large-scale in-the-wild robot manipulation data.
Why Scale Is Different in Robotics
Scaling robot data is not just collecting more files. It requires scaling along several axes at once:
- Embodiment diversity: robot arms, mobile manipulators, bimanual systems, quadrupeds, humanoids, and different grippers.
- Task diversity: pick-and-place, opening drawers, tool use, cleaning, cooking, folding, navigation, and long-horizon manipulation.
- Scene diversity: labs, homes, offices, kitchens, cluttered workspaces, changing lighting, and unseen object layouts.
- Control diversity: joint commands, end-effector deltas, gripper actions, mobile-base controls, and different frequencies.
- Annotation diversity: language instructions, success labels, object metadata, robot state, camera calibration, and teleoperation signals.
The hard part is that these axes interact. More environments help only if the policy can interpret them. More embodiments help only if the model has a way to normalize observations and actions. More tasks help only if evaluation can separate real generalization from memorization.
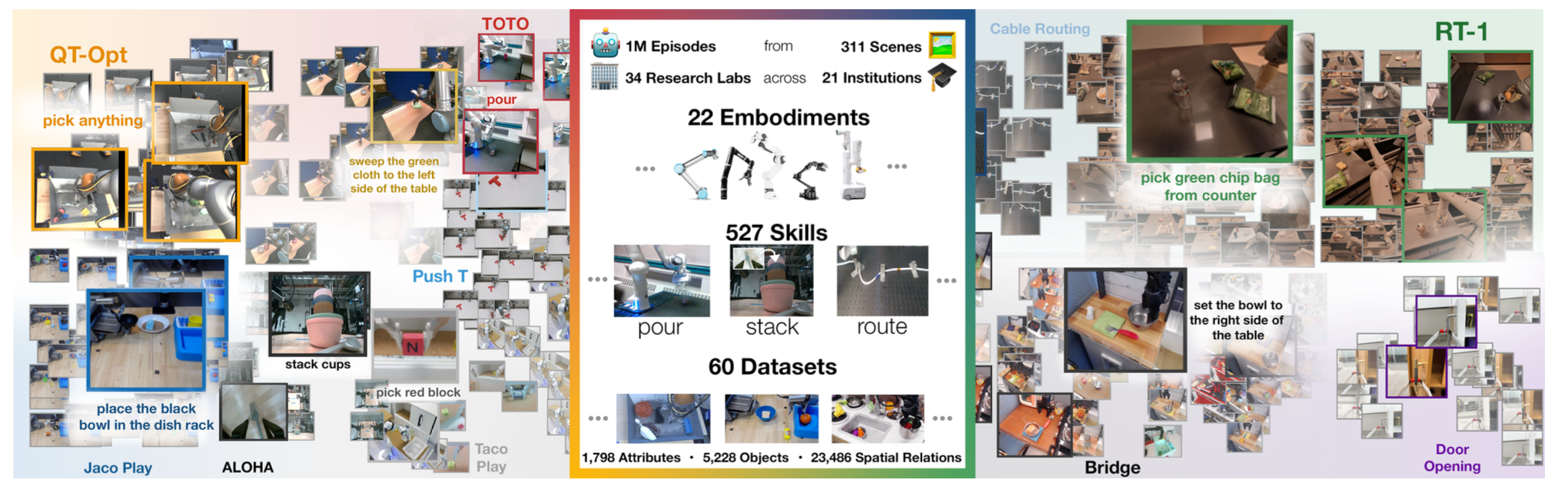
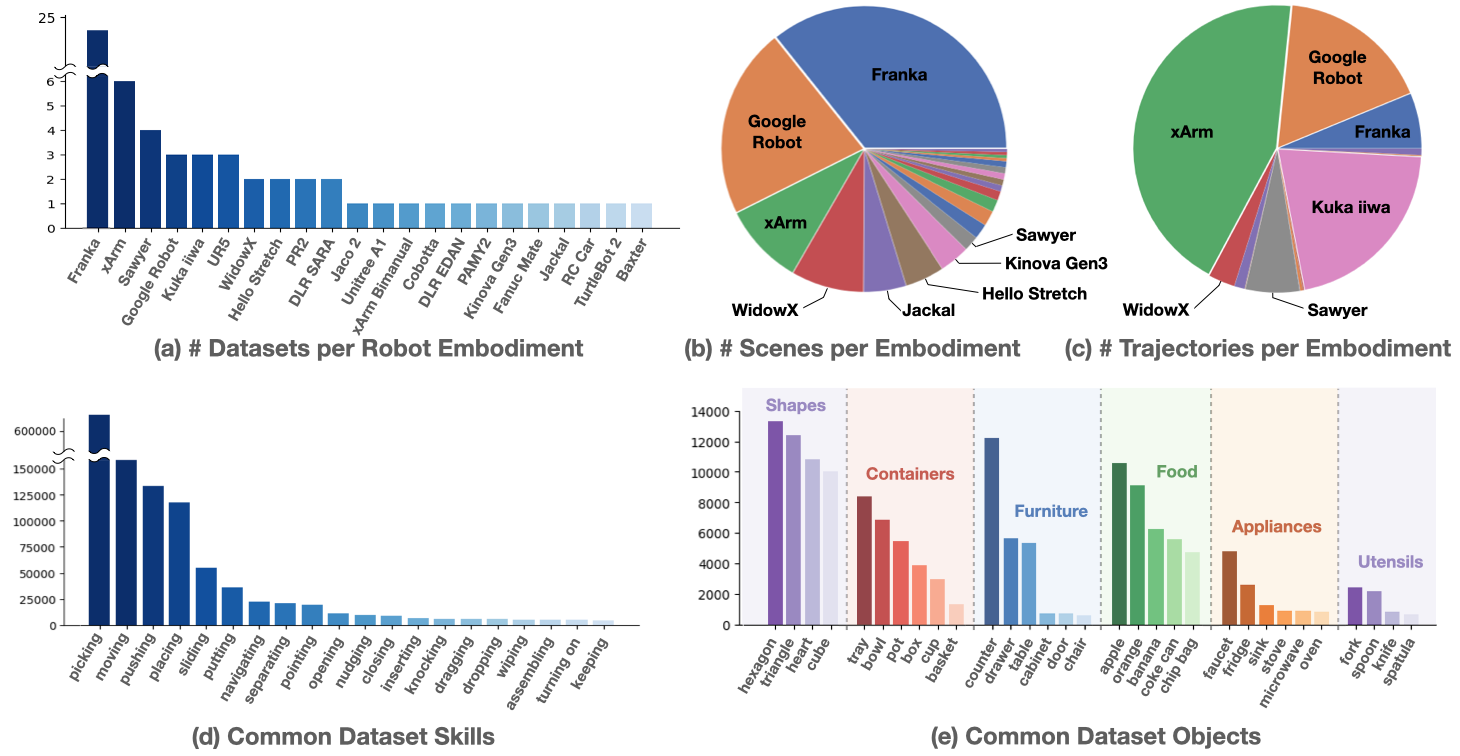
Open X-Embodiment: Standardizing Heterogeneous Robot Experience
Open X-Embodiment asks a central question: can robotics build something like a shared pretraining substrate, instead of training a separate policy for each robot and task?
The project aggregates robot demonstration datasets across many institutions and embodiments, using a standardized data format so that policies can be trained on heterogeneous robot experience. This matters because individual robot datasets are usually narrow. A lab may have many demonstrations for one arm, one camera setup, and one task family, but little evidence about whether the learned representation transfers.
The useful idea is not that all robots become identical. They do not. The useful idea is that a model can learn reusable visual, semantic, and behavioral structure across different robot streams. For example, reaching toward an object, aligning a gripper, or responding to a language instruction can share structure even when the exact action representation differs.
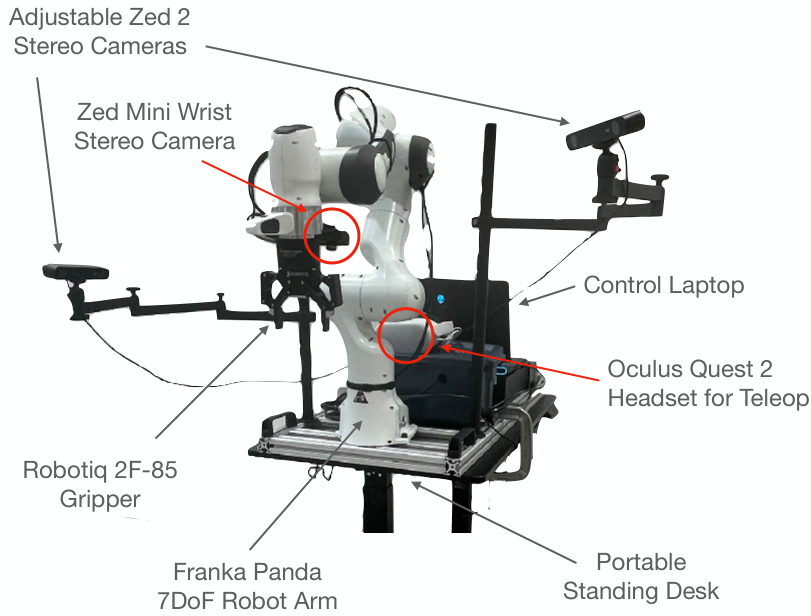
DROID: Moving Data Collection Into the Wild
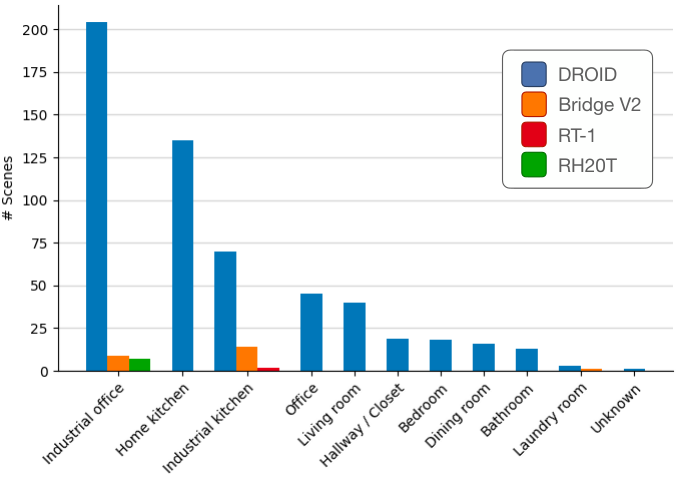
DROID takes a complementary route. Instead of mainly consolidating existing datasets, it emphasizes large-scale data collection across diverse real-world scenes. The project reports 76k demonstration trajectories, roughly 350 hours of interaction data, hundreds of scenes, dozens of tasks, and many human data collectors.
This matters because many robot policies fail not on the nominal task, but under environmental variation: different tables, lighting, object arrangements, kitchens, offices, and human preferences. If a model only sees clean lab scenes, it may learn a brittle shortcut that disappears in ordinary homes.
What Makes a Robot Dataset Useful?
A large dataset is not automatically a useful dataset. For robot policies, the most important properties are often:
- Coverage: Does the dataset contain the objects, scenes, tasks, and failure modes that matter?
- Consistency: Are observations, actions, timestamps, calibration, and language annotations aligned?
- Quality: Are demonstrations successful, smooth, diverse, and reproducible?
- Embodiment metadata: Can a model tell which robot produced which action space?
- Evaluation split design: Are test tasks genuinely different, or only visually shuffled versions of training tasks?
The fifth point is easy to miss. If train and test scenes are too similar, a policy can look general while relying on accidental correlations. If test scenes are too different without careful analysis, failure may reflect missing sensors or hardware mismatch rather than algorithmic weakness.
The Policy Perspective
From a policy-learning perspective, large robot datasets support three increasingly ambitious goals.
First, they can train stronger specialist policies by exposing the model to more instances of a task. A pick-and-place policy trained on many objects and backgrounds is less likely to overfit one table.
Second, they can pretrain generalist policies that are later fine-tuned to a new robot, task, or environment. This is the robotics analogue of starting from a pretrained language or vision model.
Third, they can enable cross-embodiment transfer, where experience from one robot helps another. This is still hard because action spaces and control dynamics vary, but shared visual and semantic structure can still be useful.
This is why VLA models such as RT-2, Octo, and OpenVLA are tightly coupled to dataset design. The model architecture matters, but the data mixture determines what the model has any chance to learn.
The Hidden Systems Work
Robot data at scale also creates systems problems:
- Storage becomes expensive because trajectories contain multi-camera videos, proprioception, and action streams.
- Data loading becomes a bottleneck when training large multimodal policies.
- Dataset schemas must preserve enough robot-specific metadata without making training impossible.
- Quality control must catch failed demonstrations, calibration issues, corrupted frames, and duplicated data.
- Evaluation must track not only success rate, but also task family, embodiment, scene type, and instruction distribution.
In practice, many robotics breakthroughs depend on this less glamorous infrastructure. The difference between a promising demo and a reusable research platform is often data curation, documentation, and reproducible loaders.
Takeaway
Open X-Embodiment and DROID represent two important answers to the same problem. Open X-Embodiment shows how existing robot experience can be standardized and pooled across embodiments. DROID shows how in-the-wild data collection can broaden the environmental distribution.
The next generation of robot foundation models will need both. Cross-robot diversity helps models learn reusable skills. Real-world scene diversity helps them survive deployment. The central question is no longer only “How big is the policy?” It is also “What physical experience did the policy learn from?”
Further Reading
- Open X-Embodiment: Robotic Learning Datasets and RT-X Models
- Open X-Embodiment project page
- DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset
- DROID project page
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- Octo: An Open-Source Generalist Robot Policy
- OpenVLA: An Open-Source Vision-Language-Action Model