Action Chunking: Why Robot Policies Predict Short Futures
A robot policy does not have to predict one action at a time. In many imitation-learning systems, the policy predicts a short sequence of future actions, then executes part of that sequence before querying the model again. This idea is called action chunking.
Action chunking is a small design choice with large consequences. It changes latency, smoothness, robustness, and how the policy handles demonstrations that are not perfectly aligned in time.
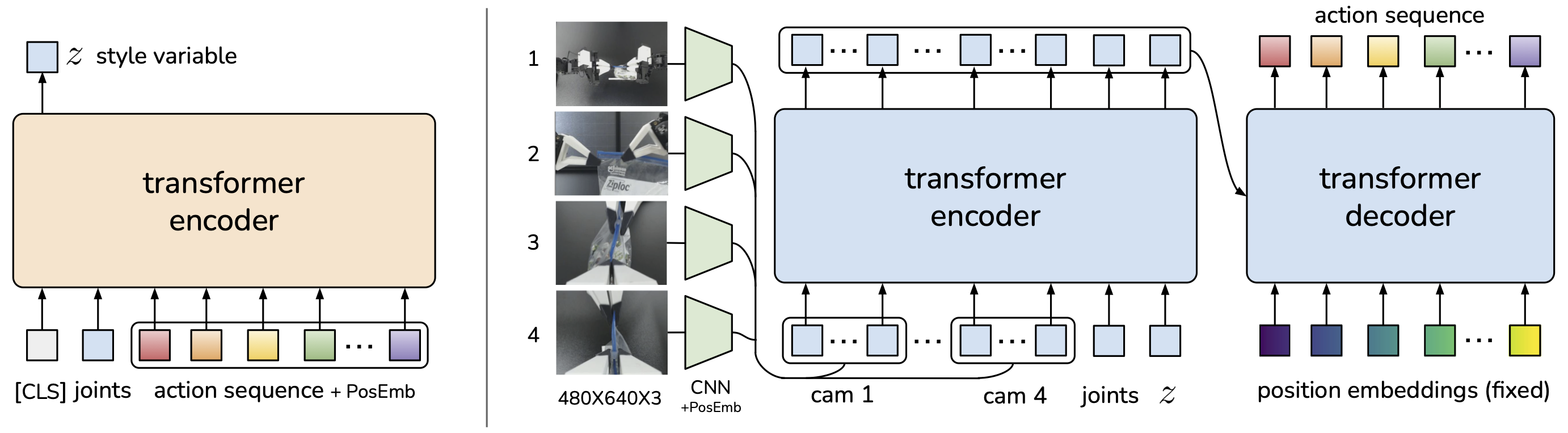
The Action Chunking Transformer, or ACT, made this idea especially visible in low-cost bimanual manipulation. ACT was introduced with ALOHA, a low-cost teleoperation and imitation-learning system for precise two-arm tasks.
The One-Step Policy Baseline
The simplest behavioral cloning policy learns:
\[a_t = \pi(o_t)\]where $o_t$ is the current observation and $a_t$ is the next action. This is conceptually clean. The robot observes the world, predicts an action, executes it, observes again, and repeats.
The problem is that real robot control is not a clean sequence of independent decisions. Actions are temporally correlated. A human demonstration is not a set of isolated motor commands; it is a coordinated motion over time. If the policy predicts each action independently, small errors can accumulate into jitter, drift, or a bad grasp.
There is also a latency problem. If a large visual policy must run at every control step, inference delay can become part of the control loop. That delay matters for contact-rich or high-frequency manipulation.
What Action Chunking Changes
Action chunking asks the model to predict:
\[a_{t:t+H} = \pi(o_t)\]where $H$ is a short horizon. Instead of asking “What is the next action?”, the model asks “What should the next small motion segment look like?”
This has three benefits.
First, the model learns smoother local motion. A chunk can represent a coherent reach, alignment, insertion, or recovery motion.
Second, the system can amortize inference. The model does not need to be queried at every low-level control step.
Third, chunking gives the policy temporal context in the output space. The model can represent the short-term structure of manipulation, not only the current state-to-action map.
Why Not Predict the Whole Task?
If predicting 10 future actions helps, why not predict 1,000?
Because the world changes. A robot may miss a grasp, an object may slip, a drawer may not open, or the camera may reveal new information. Long open-loop action sequences become brittle because they ignore feedback.
Action chunking works best as a compromise. The chunk is long enough to give smooth local behavior, but short enough that the robot can re-observe and correct itself.
This is the same design tension that appears in replanning. Too much planning wastes time and may become stale. Too little planning creates myopic, jittery behavior. Action chunking lives in the middle: short-horizon commitment plus frequent feedback.
Temporal Ensembling
ACT also uses temporal ensembling. At different time steps, the policy predicts overlapping action chunks. The controller can combine predictions for the same future time step, often weighting newer predictions more heavily.
This is useful because a single chunk may be noisy. Overlapping chunks give multiple estimates of near-future actions. Ensembling smooths the final command stream and reduces abrupt changes.
Conceptually, this turns the policy into a rolling local planner. It repeatedly proposes short futures and blends them into executable motion.
Relation to Diffusion Policy
Diffusion Policy also predicts action sequences, but it uses a different generative mechanism. Instead of directly outputting a chunk with a transformer decoder, it represents action generation as a conditional denoising process.
The shared lesson is that robot actions often have multi-modal structure. There may be several valid ways to grasp an object, open a lid, or route around an obstacle. Predicting an action sequence gives the policy a richer output object than a single command.
The difference is trade-off. ACT-style chunking is lightweight and direct. Diffusion-style action generation can model richer distributions, but may cost more inference time depending on the number of denoising steps and implementation details.
Where Action Chunking Helps
Action chunking is especially useful when tasks require:
- smooth motion over short horizons;
- precise bimanual coordination;
- contact-rich manipulation;
- low-latency execution;
- demonstrations with temporal variability;
- recovery from small state deviations.
It is less obviously useful when a task is purely reactive, when the low-level controller already handles all temporal structure, or when the environment changes so quickly that even short chunks become stale.
A Systems View
From a systems perspective, action chunking is about compute placement. A large policy can run at a moderate rate, while a lower-level controller executes high-frequency commands. This separation becomes important when policies use large visual encoders, VLA backbones, or remote inference.
The question is not only “Which model is most accurate?” It is also:
- How often must the policy run?
- How many future actions should it predict?
- How much feedback is lost during execution?
- How should old and new chunks be blended?
- How does the action horizon interact with replanning?
These choices determine whether a learned policy feels stable on real hardware.
Takeaway
Action chunking is a practical answer to a simple observation: robot behavior is temporally structured. Predicting one command at a time can be too noisy and too expensive. Predicting the whole task can be too brittle. Predicting a short future gives the policy enough temporal structure to act smoothly while still preserving feedback.
This is why action chunking keeps appearing in modern robot learning. It is not only an algorithmic trick. It is a control-interface design choice between perception, policy inference, and low-level execution.