Diffusion Policy: Generating Robot Actions by Denoising
Diffusion models are best known for generating images, but the same idea can be used for robot control. Instead of denoising pixels into an image, a robot policy can denoise random noise into an action sequence. This is the central idea behind Diffusion Policy.
The shift is useful because robot actions are not always well represented by a single deterministic output. Human demonstrations can be multimodal: two different trajectories may both solve the task. Actions also need temporal consistency. A robot should not jitter between modes at every step.
Diffusion Policy treats visuomotor control as conditional generation. Given recent observations, it generates a short horizon of future actions through an iterative denoising process, then executes part of that sequence before replanning.
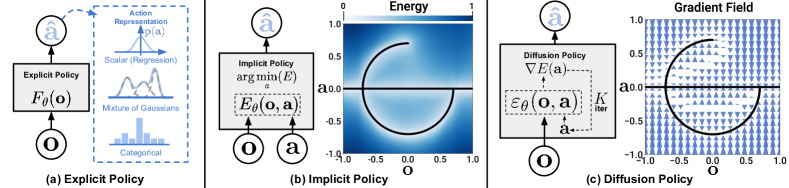
Behavior Cloning Is Not Just Regression
In imitation learning, a common starting point is behavior cloning: collect demonstrations and train a policy to map observations to actions. If the action distribution is simple, this can look like ordinary supervised regression.
Robot demonstrations are often not simple.
Consider pushing an object around an obstacle. A human may go left or right, and both choices may be valid. If a model averages those demonstrations, it may predict an action that goes through the obstacle or hesitates between modes. This is the classic problem of multimodal action distributions.
The policy also needs smoothness across time. Even if each individual action is plausible, the sequence can be bad if consecutive actions switch between incompatible modes.
Diffusion Policy addresses both issues by generating an action sequence, not only a single action.
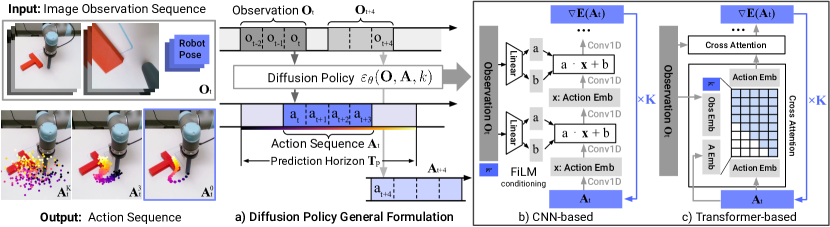
From Image Diffusion to Action Diffusion
In an image diffusion model, training adds noise to an image and learns a neural network that predicts how to remove the noise. At inference time, the model starts from random noise and repeatedly denoises until it obtains a sample.
Diffusion Policy uses the same structure, but the sample is an action trajectory:
\[A = (a_t, a_{t+1}, \ldots, a_{t+H-1})\]The policy is conditioned on observations such as camera frames, robot state, or task context. The model learns to predict the noise or score of the action sequence under that conditioning.
The result is a conditional generative policy:
\[p(A \mid O)\]where $O$ represents recent observations and $A$ is a future action chunk.
This is different from direct regression. The policy can represent multiple possible action modes and sample one coherent trajectory from them.
The Closed-Loop Recipe
Diffusion Policy is not an open-loop plan that runs forever. It is combined with receding-horizon control.
At each control cycle, the robot observes the current scene, predicts a sequence of future actions, executes only the first part of that sequence, then observes again and replans. This gives two benefits:
- the action sequence encourages temporal consistency;
- the repeated replanning keeps the policy responsive to new observations.
This design is especially important for physical robots. Contact dynamics, small perception errors, object slip, and human perturbations can make a long open-loop rollout unreliable.
Why This Helps Robot Learning
Diffusion Policy has several properties that make it attractive for visuomotor control.
First, it can model multimodal behavior. When several trajectories are valid, diffusion sampling can commit to one mode instead of averaging them.
Second, it naturally handles high-dimensional outputs. A future action chunk is higher-dimensional than a single action, but diffusion models are designed for high-dimensional generation.
Third, training is often stable compared with some energy-based policy formulations. The model learns denoising targets rather than relying on difficult negative sampling over actions.
Fourth, it fits visual conditioning. A camera encoder can produce observation features, and the diffusion model can generate actions conditioned on those features.
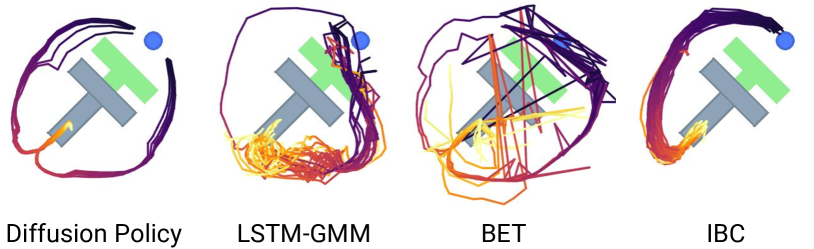
Multimodality in Practice
The most intuitive demonstration is a task with two valid paths. A robot end-effector may go around an object from the left or from the right. A direct regression policy may average the two paths. A policy that samples each step independently may switch modes and become jittery.
Diffusion Policy can sample a full action trajectory that commits to one route for the rollout. The next control cycle may re-evaluate from the new observation, but within the predicted chunk the behavior remains coherent.
The Cost of Iterative Denoising
Diffusion policies are powerful, but they introduce inference cost. Generating an action sequence may require multiple denoising steps. A robot controller cannot wait too long before acting.
The paper uses faster sampling strategies, such as DDIM-style inference, to reduce the number of denoising steps. It also separates visual feature extraction from repeated denoising so the image encoder is not recomputed unnecessarily at every denoising iteration.
This creates a familiar robotics tradeoff:
- more denoising steps can improve sample quality;
- fewer denoising steps reduce latency;
- longer action horizons improve temporal consistency;
- shorter execution horizons improve responsiveness.
Good deployment requires choosing these horizons and inference settings based on the robot, task, controller frequency, and compute budget.
Diffusion Policy Versus VLA Models
Diffusion Policy and vision-language-action models are related but not identical.
Diffusion Policy is primarily a visuomotor imitation learning method. It learns action generation from demonstrations and focuses on producing smooth, multimodal action sequences.
VLA models connect vision, language, and action, usually with broader semantic pretraining. They aim to follow language instructions and generalize across tasks, objects, and settings.
In practice, these ideas can be combined. A high-level VLA model might interpret the task and choose goals, while a diffusion action head or low-level policy generates smooth motor commands. Recent robotics systems increasingly mix language-conditioned planning with action-generation modules that handle continuous control.
Where It Can Fail
Diffusion Policy still depends on demonstration coverage. If the training data never shows recovery from a failure state, the policy may not know how to recover.
It can also be sensitive to action representation, controller design, camera setup, and latency. A model that works well in simulation may need careful observation normalization and real-world calibration. The denoising model can generate coherent actions, but it does not automatically guarantee safety, force control, or constraint satisfaction.
Finally, diffusion sampling adds system complexity. A practical robot system must manage inference timing, GPU availability, replanning frequency, and fallback behavior.
Takeaway
Diffusion Policy is a useful example of generative modeling moving from images into robot action spaces. Its key contribution is not simply “using diffusion for robotics.” The important design is conditional action-sequence generation inside a closed-loop, receding-horizon controller.
The mental model is:
- observe the scene;
- sample a coherent future action sequence by denoising;
- execute a short prefix;
- observe again and replan.
This makes diffusion a natural tool for robot manipulation tasks where actions are continuous, multimodal, and temporally correlated.
Further Reading
- Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- Diffusion Policy project page
- Denoising Diffusion Probabilistic Models
- Diffuser: Diffusion Models for Offline Reinforcement Learning
- Behavior Transformers: Cloning k Modes with One Stone
- pi0: A Vision-Language-Action Flow Model for General Robot Control