From VLM to VLA to WAM: What Changes When Models Start Acting?
The move from Vision-Language Models (VLMs) to Vision-Language-Action Models (VLAs) and then to World Action Models (WAMs) is often described as a sequence of acronyms. That framing is convenient, but it hides the important point. These are not just three model names. They are three different contracts between a model and the world.
A VLM is mostly asked to interpret. Given an image and a prompt, it returns text. A VLA is asked to intervene. Given an observation and an instruction, it returns robot actions. A WAM goes further: it asks the model to couple action with predicted consequence. The output is no longer only “move the robot this way,” but also a representation of how the world should evolve if that action is reasonable.
This distinction matters because acting changes the failure mode. A weak caption can be ignored. A weak action may move the robot into a bad state. A weak future model may produce visually plausible but physically wrong rollouts that mislead a planner. Once the model is inside the control loop, semantics, latency, embodiment, dynamics, and uncertainty become inseparable.
This post uses several papers as anchors: RT-2, OpenVLA, DreamZero, and Fast-WAM. The figures below are converted from the authors’ arXiv LaTeX source rather than hand-drawn diagrams.
The Output Contract
The simplest way to separate the three families is to look at what the model is trained to emit.
| Model family | Typical input | Typical output | Main question |
|---|---|---|---|
| VLM | Image or video plus language | Text, labels, answers, descriptions, plans | What is in the scene, and what does it mean? |
| VLA | Robot observation, language, sometimes proprioception | Action tokens, continuous commands, or action chunks | What should the robot do next? |
| WAM | Observation history, language, action context, sometimes proprioception | Actions jointly modeled with future observations, video, states, or latents | What action should be taken, and what future does it imply? |
The differences look small on paper, but each column changes the system. Changing the output from text to action changes data collection, loss design, safety constraints, timing, and evaluation. Adding future prediction changes the role of representation learning and introduces a new compute question: should the robot explicitly imagine future observations online, or should future prediction mainly shape the model during training?
VLMs: Semantics Without Physical Commitment
VLMs connect visual inputs to language. In robotics, this gives a robot useful semantic priors: object names, spatial relations, affordance-like knowledge, commonsense context, and task descriptions. A VLM can often tell that a mug is on the table, that a sponge is useful for cleaning, or that a drawer must be opened before an object can be placed inside it.
But a VLM usually does not control the robot directly. It can say “pick up the red cup,” but it does not by itself specify the end-effector delta, gripper command, control frequency, recovery behavior, or when the current plan has become invalid. Even if a VLM produces a high-level plan, the execution is usually delegated to another policy, controller, or hand-coded skill.
That separation is useful, but it also creates a bottleneck. Semantic knowledge remains outside the low-level control policy. The robot may understand the instruction at the language level while still failing at grasp selection, contact-rich motion, timing, or closed-loop correction. This is the gap that VLA models try to close.
RT-2: Actions As Language Tokens
RT-2 is a clean example of the VLA idea. Instead of treating robot control as a separate module downstream of a VLM, RT-2 folds robot actions into the token interface. The model is co-fine-tuned on web-scale vision-language tasks and robot trajectory data. At inference time, action tokens are decoded into robot commands for closed-loop control.
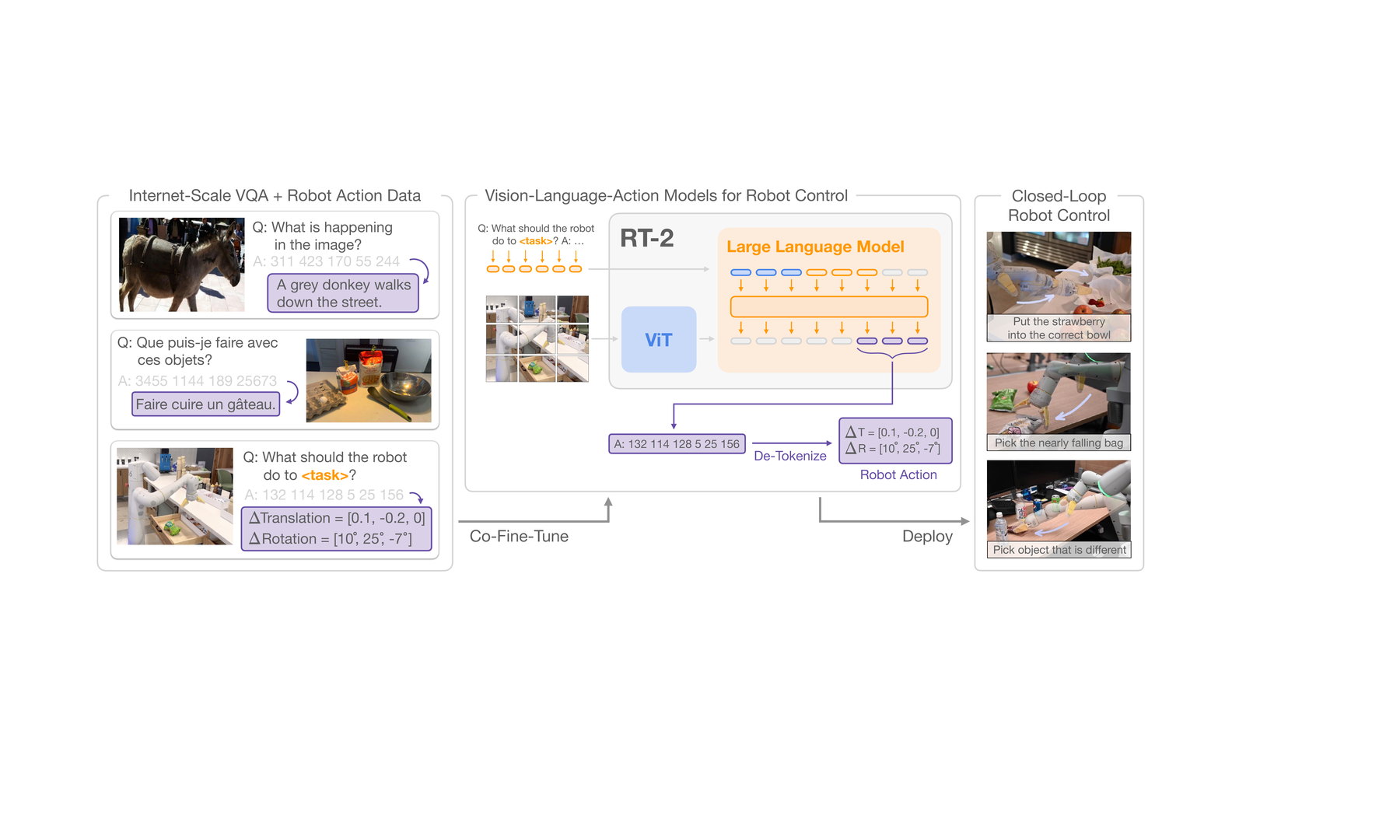
This is more than an implementation trick. It changes what the model is responsible for. A VLM can describe an object. A VLA must map that object, the instruction, and the robot’s current configuration into executable control. A simplified VLA policy can be written as:
\[\pi(a_t \mid o_t, l)\]where (o_t) is the current observation, (l) is the language instruction, and (a_t) is the next robot action or action chunk. In practice, the observation may include multiple camera views and proprioceptive state. The action may be discretized tokens, continuous end-effector deltas, joint commands, gripper states, or a short horizon of commands.
The important RT-2 lesson is that web-scale visual and language pretraining can become useful for robotic control only after the action interface is made compatible with the pretrained model. If actions are represented as tokens, the model can reuse a language modeling objective. If actions are represented as continuous vectors, the system needs an action head, a diffusion or flow objective, or another continuous prediction mechanism. Either way, the model architecture is no longer just a VLM. It has become a policy.
That new responsibility produces new constraints.
First, the policy must run at a useful rate. Second, action errors are not independent: a small mistake changes the next observation. Third, embodiment matters. A token that maps to a gripper command for one robot is not automatically meaningful for another robot. Fourth, evaluation moves from language accuracy to task success, recovery, robustness, and latency.
OpenVLA: Making the VLA Stack Explicit
OpenVLA is useful because it makes the engineering stack explicit and open. It builds a 7B-parameter VLA with a visual encoder, a projector into the language embedding space, and a Llama 2 backbone. The model predicts 7-dimensional robot control actions from image observations and language instructions, and it is trained on a large mixture of real robot demonstrations from Open X-Embodiment.
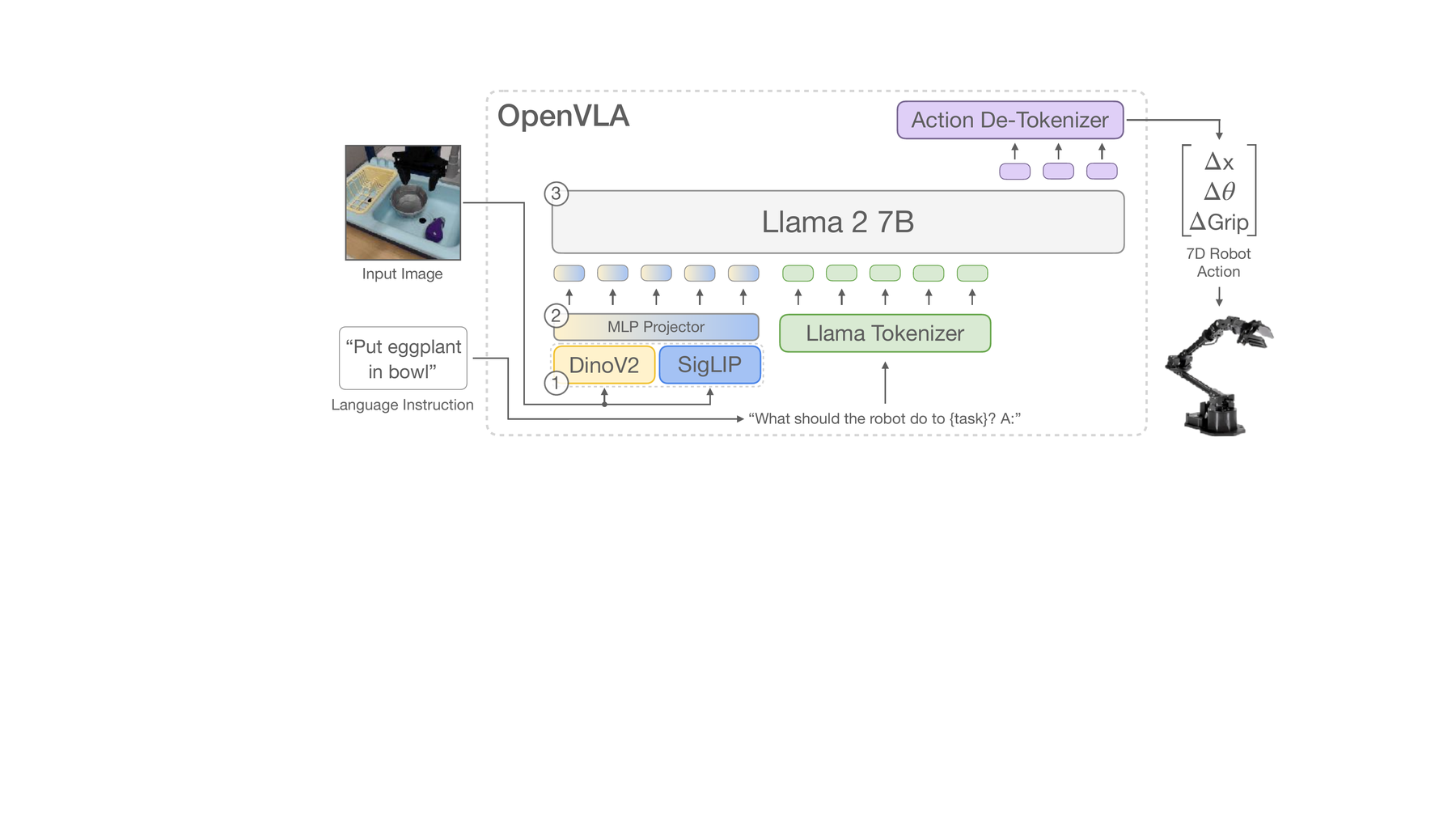
OpenVLA clarifies several practical issues that are easy to miss when we talk only about “generalist robot models.”
The first issue is data mixture. Robot datasets are not like web image-text corpora. They contain different robots, camera placements, control conventions, task distributions, teleoperation quality, and annotation styles. A VLA trained across many embodiments must learn what is shared and what is embodiment-specific.
The second issue is adaptation. A general VLA may not work out of the box in a new lab with a different gripper, workspace, camera calibration, or object set. Parameter-efficient fine-tuning, quantization, and inference serving become part of the research problem because the model must be usable by real robotics groups, not only by the team that trained it.
The third issue is action representation. The model may inherit semantic knowledge from VLM pretraining, but the action head defines how that knowledge touches the robot. A weak action representation can waste a strong backbone. A strong action representation can make a smaller model much more useful.
So the transition from VLM to VLA is not simply “add an action token.” It is a shift from recognition to control. The model becomes an online component of a dynamical system.
What Changes When the Model Starts Acting?
There are at least six changes that matter in practice.
1. Time becomes part of correctness. A VLM answer can be slow and still be correct. A robot action that arrives too late can destabilize the control loop, miss a moving object, or cause the policy to over-correct.
2. Errors become state-changing. A wrong answer in a caption usually does not alter the image. A wrong action changes the next observation. It can push an object out of reach, close a drawer, drop a tool, or occlude the target.
3. The output is embodiment-bound. Text is portable across platforms. Robot actions are not. The same instruction may require different action spaces, controller gains, camera viewpoints, and safety limits on different robots.
4. Dataset coverage becomes physical coverage. VLM pretraining can benefit from enormous web corpora. Robot data is harder to scale because it requires physical interaction. The policy must generalize over contact, object geometry, friction, lighting, workspace layout, and recovery cases.
5. Evaluation becomes intervention-based. We cannot judge a VLA only by whether its action looks plausible. We care whether the robot completes the task, how many interventions it needs, whether it recovers after disturbances, and whether it respects hardware limits.
6. Compute becomes a control resource. A language model can spend seconds reasoning before answering. A robot may need to act at 5 Hz, 10 Hz, or faster. If a model spends too long planning or imagining, the world changes while it thinks.
These constraints explain why VLA systems are not just VLMs with new output tokens. Acting turns model design into a systems problem.
Why VLA Policies Can Still Be Too Reactive
Many VLA policies are trained to map the current observation to the next action or short action chunk:
\[\pi(a_t \mid o_{\leq t}, l)\]This is powerful when the next action is visible from the current context. It works well for many manipulation tasks where the policy only needs to localize the object, move toward it, grasp, and place.
But long-horizon behavior often requires asking counterfactual questions. What happens if I pull the cloth from this side? Will the cup become occluded if I move the plate first? Should I reposition before grasping? If two agents act in the same workspace, will my current action block the other robot? If the robot only predicts the next action, it may learn good local reactions without learning enough about consequences.
This is where the world-model tradition becomes relevant. Classical world models learn a predictive model of environment dynamics and use it for imagination, planning, or representation learning. In embodied foundation models, the question becomes more specific: can we combine the semantic generality of VLM/VLA pretraining with an action-conditioned model of how the physical scene changes?
That question motivates WAMs.
WAMs: Actions Coupled To Future World State
In this post, I use World Action Model in a specific embodied-control sense: a model that learns actions together with future world states, observations, video, or latent representations. A simplified target is:
\[p(a_{t:t+H}, o_{t+1:t+H} \mid o_{\leq t}, l)\]This differs from a standard VLA in two ways. First, the model is not only supervised to output an action. It is also pressured to represent the future that action should create. Second, the prediction target can provide dense supervision about physical dynamics even when action labels are sparse, noisy, or embodiment-specific.
There are several possible roles for the future prediction objective:
- It can act as a training signal that shapes a physically meaningful representation.
- It can act as an online planner that lets the robot compare possible futures before choosing an action.
- It can act as a consistency check: if the predicted future is implausible, the policy may need to replan or ask for more information.
- It can support cross-embodiment transfer because video can describe task dynamics even when the action spaces differ.
The hard part is deciding which of these roles is actually needed at deployment time.
DreamZero: A WAM Built On Video And Action
DreamZero is a direct WAM example. It builds on a pretrained video diffusion backbone and jointly models future video and robot actions. The paper’s core claim is that WAMs can inherit useful physical priors from video generation while learning executable robot behavior from heterogeneous data.
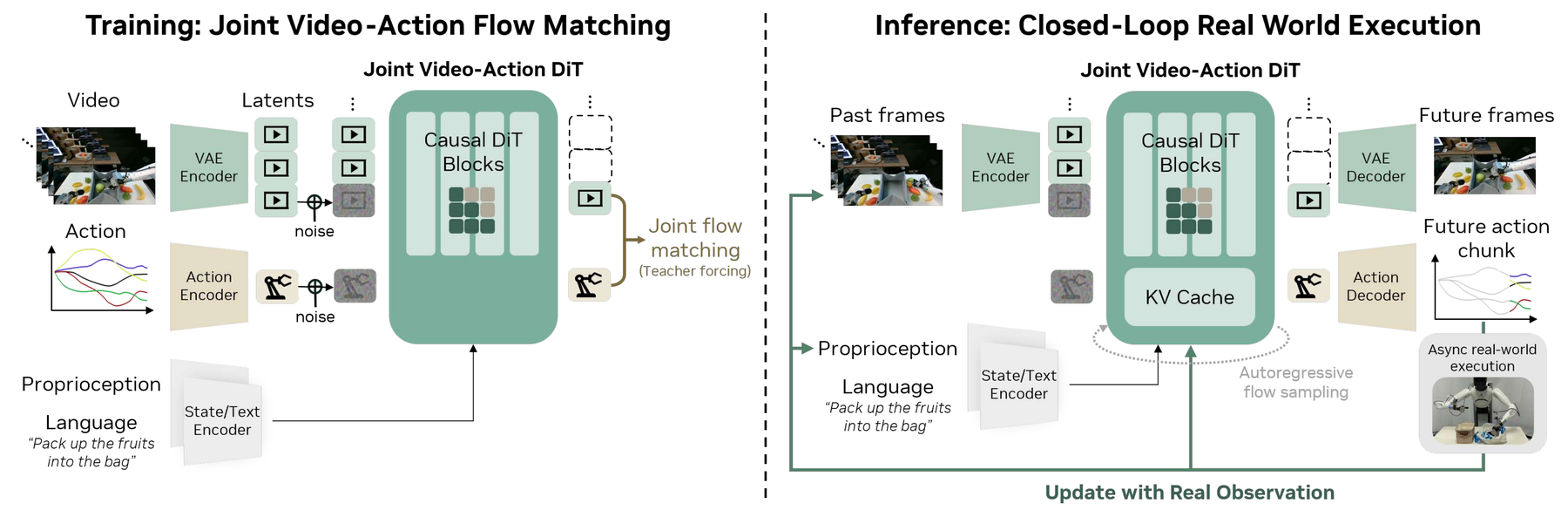
The architectural idea is important. The model consumes visual context, language, and proprioceptive state. It uses an autoregressive diffusion-transformer-style backbone and predicts future video and actions through separate decoders. During closed-loop control, real observations are fed back so that execution is not purely open-loop imagination.
This gives WAMs a different failure surface from standard VLAs. A VLA can fail because it predicts a wrong action. A WAM can fail because its imagined future is wrong, because action and video are misaligned, because the future prediction is too slow, or because the model faithfully executes a visually plausible but task-incorrect rollout.
At the same time, the advantage is clear. If video prediction teaches the model object permanence, contact progression, motion continuity, and task dynamics, then action prediction is no longer learned from action labels alone. The model can absorb structure from visual experience.
This is especially relevant for transfer. Action spaces differ across robots, but videos of task progress can be more comparable. A human opening a drawer, a bimanual robot manipulating fabric, and a single-arm robot moving objects are not the same embodiment, but they may share visual-temporal structure. A WAM gives the model a place to learn that structure.
Fast-WAM: Does The Robot Need To Imagine Online?
The obvious WAM design is “imagine, then act.” Generate a possible future, condition action prediction on that future, and execute. That is intuitive, but it raises a serious robotics question: can the robot afford it?
Fast-WAM asks whether the benefit of WAMs comes from explicit future generation at test time or from video co-training during training. It keeps video modeling as a training signal but removes explicit future video generation during inference, predicting actions in a single forward pass from learned world representations.
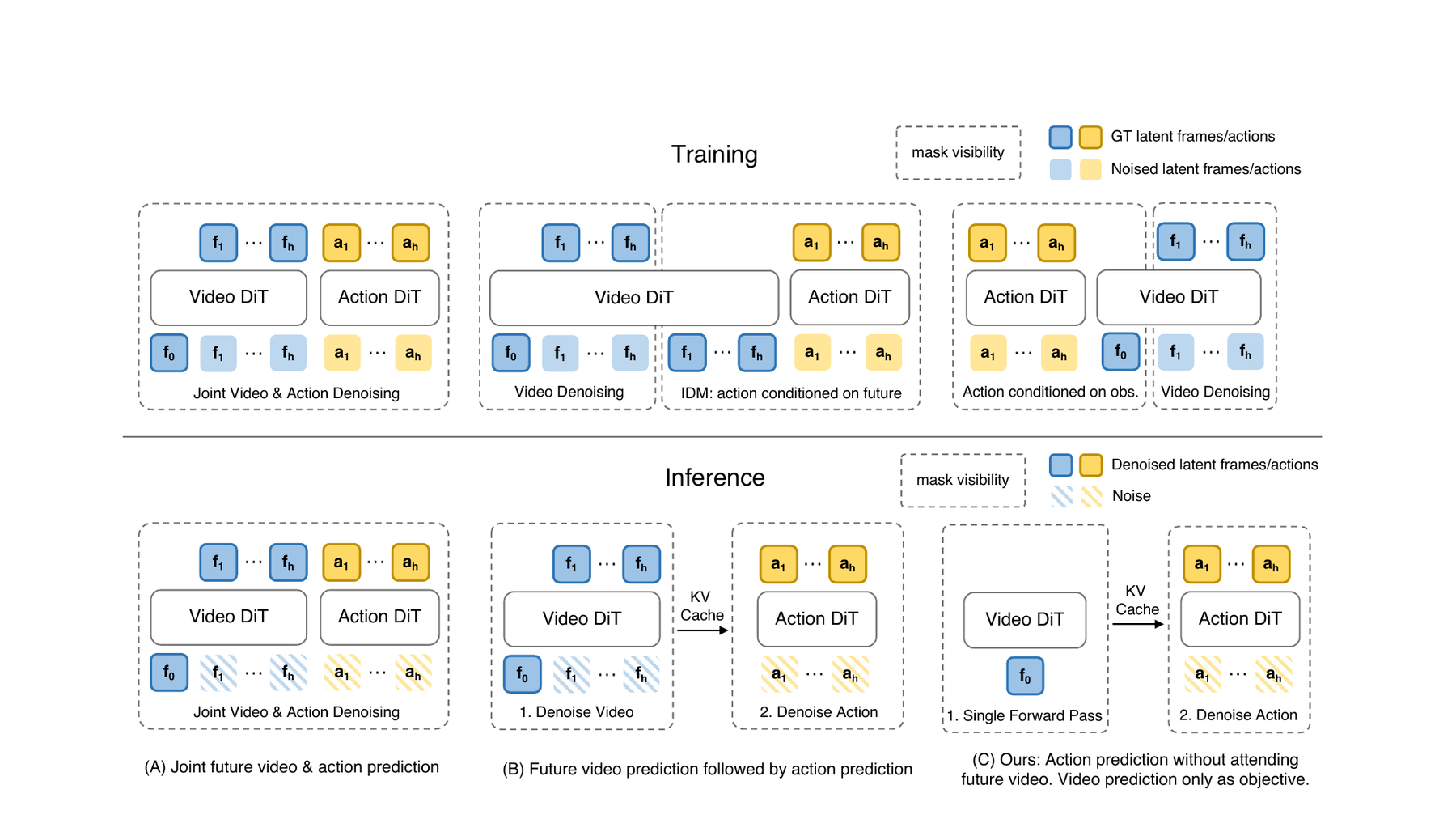
This distinction is useful beyond one paper. It separates two hypotheses that are often bundled together:
Hypothesis A: future prediction is useful because it improves the internal representation during training.
Hypothesis B: future prediction is useful because the robot needs explicit imagined frames during inference.
Both can be true, but they imply different systems. If Hypothesis A is the main effect, then WAM-style objectives can be used to pretrain or co-train stronger policies without paying a heavy online latency cost. If Hypothesis B is essential, then the system needs an online planning loop that can afford the cost of imagination and still act in time.
For real robots, this is not a minor implementation detail. It determines whether the world model is part of every control step, part of occasional replanning, or only part of offline training.
A Better Mental Model
I find it useful to separate the three families by where uncertainty lives.
VLMs are useful when the main uncertainty is semantic: What object is this? What does the instruction refer to? Which object is likely the tool? What is the relation between the objects?
VLAs are useful when the main uncertainty is action selection: Given this observation and instruction, what command should move the robot toward success?
WAMs are useful when the main uncertainty is consequence: If the robot takes this action, what future state should it expect, and does that future make sense for the task?
This means WAMs should not be viewed as a replacement for VLAs in every setting. A simple pick-and-place task may not need expensive imagination at each step. A long-horizon task with occlusion, deformable objects, multi-agent coordination, or sparse rewards may benefit much more from predictive structure.
The design question is therefore not “VLA or WAM?” The better question is:
Where should prediction live in the system, given the task horizon, latency budget, robot hardware, and cost of failure?
Replanning As The Hidden Bottleneck
Once a model can act and predict, the next issue is replanning. A real robot cannot spend unlimited compute imagining futures after every frame. It also cannot blindly execute a long action chunk when the world has changed. The system needs a budgeted loop:
\[\text{observe} \rightarrow \text{infer} \rightarrow \text{act} \rightarrow \text{predict} \rightarrow \text{check} \rightarrow \text{replan}\]This loop creates several practical questions.
How long should an action chunk be? Short chunks give more feedback but require more inference. Long chunks are efficient but increase open-loop risk. When should the robot replan? Replanning too often wastes compute and may make the policy jittery. Replanning too rarely lets errors compound. Should the future model run onboard, on an edge server, or only offline? The answer depends on bandwidth, safety requirements, and robot speed.
This is where VLA and WAM research becomes a systems problem. The best policy is not only the one with the highest offline accuracy. It is the one that allocates compute correctly between fast action, semantic reasoning, predictive modeling, and recovery.
Practical Design Lessons
Several lessons fall out of the VLM-to-VLA-to-WAM progression.
Do not equate visual understanding with control. A model can understand a scene and still fail to act. Control needs timing, embodiment, feedback, and recovery.
Treat action representation as a core interface. Tokenized actions, continuous actions, diffusion heads, flow heads, and action chunks each create different inductive biases. This choice determines how semantic knowledge reaches the robot.
Use future prediction for a specific purpose. Future prediction can be a representation-learning objective, an online planner, a consistency check, or a data bridge across embodiments. These uses should not be conflated.
Measure latency together with success. A high-quality imagined future is not useful if it arrives too late for the control loop. Robotics evaluation should report both task performance and timing behavior.
Evaluate recovery, not only first-attempt success. Acting systems should be judged by how they behave after distribution shift, partial failure, occlusion, object movement, and bad intermediate states.
Expect hybrid deployment. A practical robot may use a large VLM-like module for semantic grounding, a faster VLA-like policy for action chunks, and a WAM-style objective or module for prediction and replanning. The modules may run at different rates and on different hardware.
Takeaway
The important change from VLM to VLA to WAM is not only larger models or more modalities. It is the transition from interpretation to intervention to consequence-aware intervention.
VLMs ground language in perception. VLAs make models responsible for robot actions. WAMs ask action models to learn how their actions reshape the world. That last step is powerful, but it is also expensive and easy to misuse. The core research problem is deciding where predictive modeling belongs: offline training, online planning, occasional replanning, uncertainty estimation, or all of the above.
For embodied agents, the future will probably not be a single monolithic model that always reasons, always imagines, and always acts at the same rate. It will be a layered system that uses semantic understanding when language matters, fast action prediction when timing matters, and world modeling when consequences matter.
Further Reading
- CLIP: Learning Transferable Visual Models From Natural Language Supervision
- Visual Instruction Tuning / LLaVA
- World Models
- DreamerV3: Mastering Diverse Domains through World Models
- RT-1: Robotics Transformer for Real-World Control at Scale
- PaLM-E: An Embodied Multimodal Language Model
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- Open X-Embodiment: Robotic Learning Datasets and RT-X Models
- Octo: An Open-Source Generalist Robot Policy
- OpenVLA: An Open-Source Vision-Language-Action Model
- pi0: A Vision-Language-Action Flow Model for General Robot Control
- DreamZero: World Action Models are Zero-shot Policies
- Fast-WAM: Do World Action Models Need Test-time Future Imagination?