Simulation as a Data Engine: RoboCasa and ManiSkill3
Robot simulation is often introduced as a benchmark: train a policy, report a success rate, compare algorithms. That view is useful, but too narrow.
For modern embodied AI, simulation is increasingly a data engine. It can generate scenes, tasks, demonstrations, failures, counterfactuals, camera views, and evaluation splits at a scale that would be expensive or unsafe in the real world. The goal is not to replace real robot data. The goal is to make robot learning more scalable, reproducible, and controllable.
Two useful examples are RoboCasa, which focuses on realistic household manipulation scenes and tasks, and ManiSkill3, which focuses on fast GPU-parallelized simulation and rendering for scalable robot learning.

Why Simulation Matters Again
Simulation has always been part of robotics, but its role changes when policies become data-hungry.
Classical simulation is often about controlled testing: does this planner collide, does this controller stabilize, does this grasp succeed in a known scene? Foundation-model-era simulation asks a broader question: can we generate enough diverse experience to train and evaluate generalist robots?
This requires more than a physics engine. A useful simulation data engine needs:
- diverse scenes;
- interactable objects;
- realistic sensors;
- many task definitions;
- scalable rendering;
- reproducible data generation;
- evaluation protocols that do not leak training conditions.
The most important feature is controllability. In real-world data collection, we observe whatever happens. In simulation, we can deliberately vary object placement, lighting, camera pose, task instruction, robot embodiment, and initial state.
RoboCasa: Household Diversity as a Design Target
RoboCasa is built around everyday household activities, especially kitchen tasks. That focus matters because household manipulation requires rich object interactions: opening cabinets, twisting knobs, pushing buttons, placing objects into containers, and sequencing multiple skills.
The core contribution is not a single environment. It is a scalable recipe for producing many scenes, objects, and tasks. RoboCasa uses diverse kitchen layouts, many object assets, interactable appliances, mobile manipulators, and task generation assisted by large language models.

The key idea is that a simulator should expose the policy to the kind of diversity that real deployment will contain. If a robot learns only one kitchen layout, one cabinet style, and one object set, it may learn brittle shortcuts. If it sees many plausible variations, the learned policy has a better chance of capturing reusable structure.
ManiSkill3: Throughput as a Research Capability
RoboCasa emphasizes scene and task diversity. ManiSkill3 emphasizes fast, scalable simulation and rendering. This matters because modern robot learning often needs many parallel environments and visual observations.
GPU-parallelized simulation changes the iteration cycle. If an environment can run thousands of instances with rendering, researchers can train and evaluate visual policies much faster. This is not only convenient. It changes what questions are practical to ask.
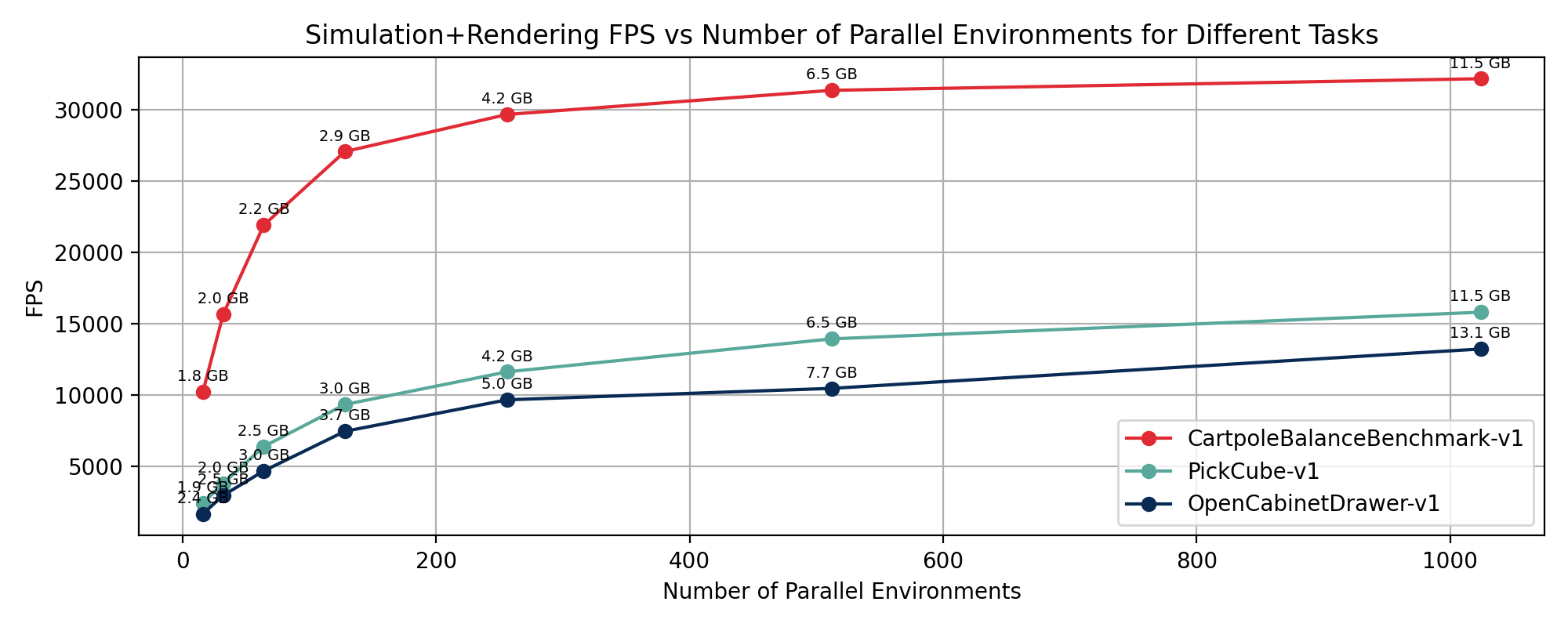
High throughput helps in several ways:
- training reinforcement learning agents with many rollouts;
- generating synthetic demonstrations or evaluation episodes;
- testing robustness across many random seeds and scene variations;
- running visual policies at scale;
- comparing algorithms under controlled conditions.
In robotics, compute efficiency is not just a systems detail. It determines whether an experiment takes hours, days, or weeks.
Simulation Is Not Just Synthetic Data
It is tempting to describe simulation as “fake data.” That is misleading. A good simulator can produce several distinct kinds of useful evidence.
First, it can generate training data: demonstrations, rollouts, expert trajectories, failed attempts, and recovery behavior.
Second, it can generate evaluation data: controlled test suites that measure generalization across objects, tasks, layouts, and embodiments.
Third, it can generate counterfactual data: what happens if the object starts slightly farther away, the drawer is already open, or a distractor appears?
Fourth, it can support debugging: when a policy fails, the environment state can be replayed, inspected, and modified.
Fifth, it can support digital twins: approximations of real scenes that let us evaluate or pretrain before touching hardware.

The Sim-to-Real Gap Is Still Real
Simulation helps, but it does not remove the need for real robot data. The sim-to-real gap appears in many forms:
- contact dynamics are hard to model;
- deformable objects are difficult;
- real cameras have noise, exposure changes, motion blur, and calibration errors;
- object assets may not match real geometry and texture;
- controllers and latency differ from real hardware;
- human environments contain unmodeled clutter and edge cases.
This is why simulation should be treated as a data engine, not a truth engine. It can produce useful variation, but every claim about deployment should eventually be checked on real hardware or at least under carefully designed real-to-sim validation.
A Good Simulation Dataset Has a Purpose
Not every synthetic trajectory is useful. A simulation dataset should be designed around a target failure mode or generalization question.
For example:
- If the goal is visual generalization, vary textures, lighting, camera views, and object appearances.
- If the goal is manipulation robustness, vary initial poses, contact conditions, object geometry, and distractors.
- If the goal is long-horizon planning, vary subtask order, hidden states, and irreversible actions.
- If the goal is cross-embodiment transfer, vary robot morphology and action spaces.
The simulator should make the intended distribution shift explicit. Otherwise, synthetic scale can hide weak evaluation.
Takeaway
Simulation is becoming a central part of the robot learning data pipeline. RoboCasa shows how scene, object, and task diversity can be scaled for household manipulation. ManiSkill3 shows how GPU-parallel simulation and rendering can make large-scale visual robot learning practical.
The useful mental model is simple: real data grounds the policy, simulation expands the distribution, and evaluation tells us whether the expansion helped. A simulator is valuable not because it is perfect, but because it lets us generate, control, and measure physical experience at a scale that real-world collection alone cannot provide.
Further Reading
- RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
- RoboCasa project page
- ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
- ManiSkill project page
- MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
- RoboSuite: A Modular Simulation Framework and Benchmark for Robot Learning