What Is Replanning in Embodied AI?
Replanning is one of the easiest ideas to explain and one of the hardest ideas to make work in embodied AI.
At a high level, replanning means updating an agent’s future actions after execution reveals new information. A robot may discover that the target object is not where the language instruction implied, a grasp may fail, a door may already be open, another agent may occupy the path, or the environment may contain objects that were not visible when the first plan was generated.
The modern replanning story is closely tied to language-model-based planning. Large language models are good at proposing high-level action sequences, but embodied execution turns planning into an interactive process. The agent has to observe, act, detect failure, revise the plan, and sometimes decide that replanning is not worth the cost.
This post follows that idea through a few representative papers: ReAct, SayCan, Inner Monologue, LLM-Planner, FLARE, and BRACE.
The Short Version
Replanning is not just “ask the model again.” A useful embodied replanning system needs three ingredients:
| Ingredient | What it answers | Representative papers |
|---|---|---|
| Grounding | Is the plan feasible in this environment? | SayCan, LLM-Planner, FLARE |
| Feedback | What happened after the last action? | ReAct, Inner Monologue |
| Budgeting | Is another planner call worth the latency and compute? | BRACE |
The difference matters. A language model can produce a plausible plan for “bring me a coke,” but a robot must know whether the coke exists, whether the grasp succeeded, whether the path is blocked, and whether waiting for another large-model call will delay execution too much.
From Reasoning-Acting Loops to Embodied Replanning
ReAct is not only a robotics paper, but it gives a useful abstraction: reasoning and acting should be interleaved. The model reasons, takes an action, observes the result, and uses that observation to update the next step. In interactive environments, this is already a form of replanning. The plan is not a static list. It is revised as the agent learns more.
The embodied version is stricter. A robot action changes the physical world, and observations can be incomplete or delayed. ReAct’s reason-act-observe pattern therefore becomes a control loop:
- Propose a next subgoal or skill.
- Execute through the robot or simulator.
- Observe the new state and execution result.
- Decide whether the current plan remains valid.
- Continue, repair, or replan.
This loop is the conceptual backbone behind many later embodied planning systems.
SayCan: Ground the Plan Before You Execute It
SayCan addresses a basic failure mode of language-only planning: a plan can be semantically reasonable but physically unavailable. A robot may know that “pick up the sponge” is useful for cleaning, but if the sponge is not reachable, the action should not be selected.
SayCan combines two scores:
- a language-model score for how useful an action is for the task;
- an affordance score for whether the robot can execute that action in the current world.
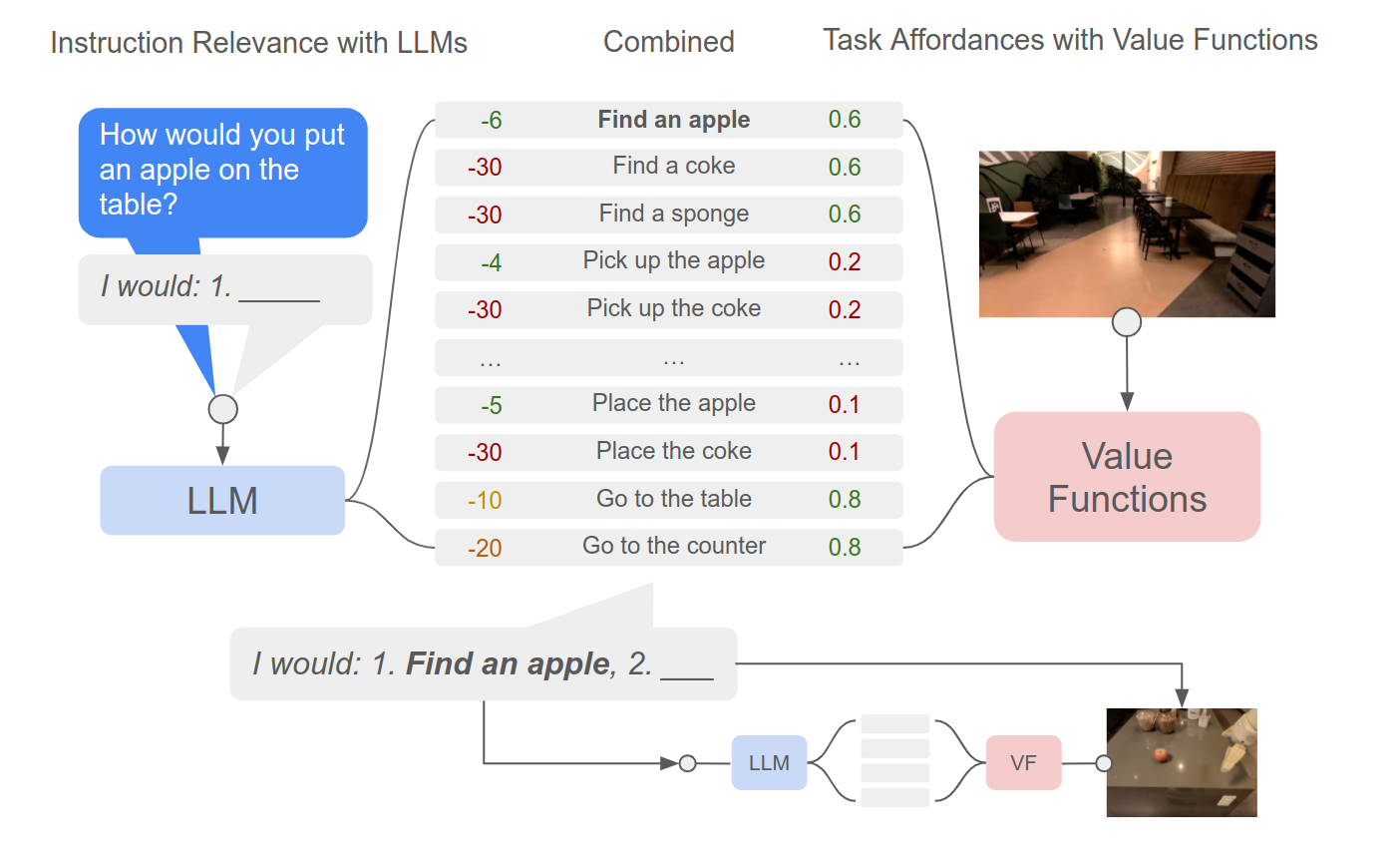
This is not replanning by itself, but it changes what replanning should optimize. A replan should not merely produce a new text plan. It should produce a plan that is grounded in current affordances.
If an action fails, the replanner should ask: did the high-level goal change, did the world state change, or was the selected action infeasible from the start?
Inner Monologue: Feedback Becomes Part of the Prompt
Inner Monologue makes the feedback loop explicit. The paper studies how language models can use environment feedback written in natural language, such as scene descriptions, success detector outputs, and human corrections.
This is important because many embodied failures are not visible in the initial instruction. The agent learns them through execution:
- “I see coke, water, chocolate bar.”
- “Action was not successful.”
- “The drawer is already open.”
- “The requested object is not visible.”
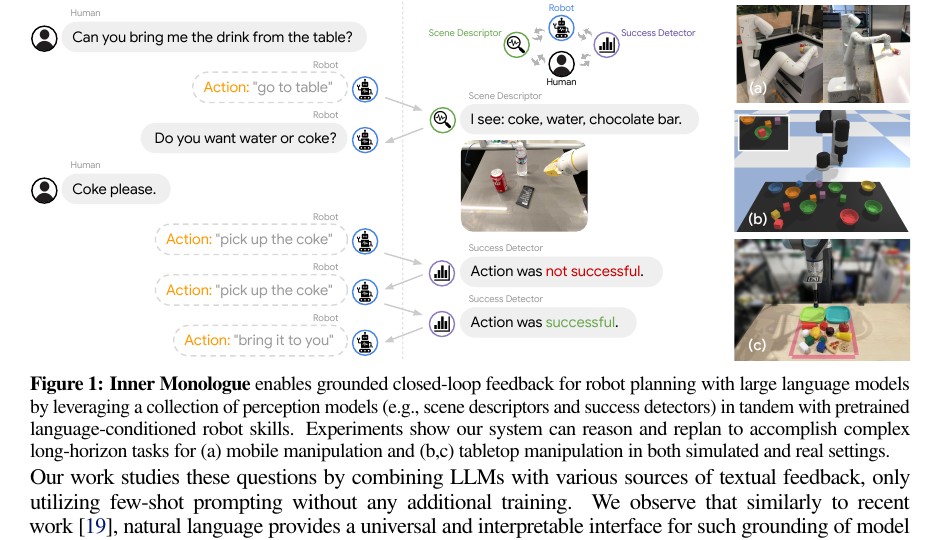
In this framing, replanning is language-conditioned feedback processing. The model updates the plan because the prompt now contains new evidence about the environment and the previous action.
This also reveals a weakness. As tasks become longer, the feedback history grows. The prompt can become long, noisy, and expensive to process. That issue becomes central later.
LLM-Planner: Replan From What Has Actually Been Observed
LLM-Planner focuses on few-shot grounded planning for embodied agents, especially on ALFRED-style long-horizon household tasks. Its key move is simple but important: when the current plan becomes unattainable or the agent repeatedly fails a subgoal, prompt the LLM again using the partial plan already completed and the objects observed so far.
That gives replanning a concrete structure:
- Keep track of completed subgoals.
- Detect that the current subgoal is failing or unreachable.
- Summarize the observed environment.
- Ask the LLM for a continuation plan grounded in those observations.
This is a more precise version of “try again.” The replanner is not starting from scratch. It is conditioned on execution history and partial progress.
FLARE: Multimodal Grounding and Adaptive Replanning
FLARE makes the visual grounding part more explicit. The paper argues that LLM planners often rely too much on linguistic common sense and ignore the actual state of the environment at command reception. To fix this, FLARE combines language instructions with environmental perception and adds an environment-adaptive replanning component.
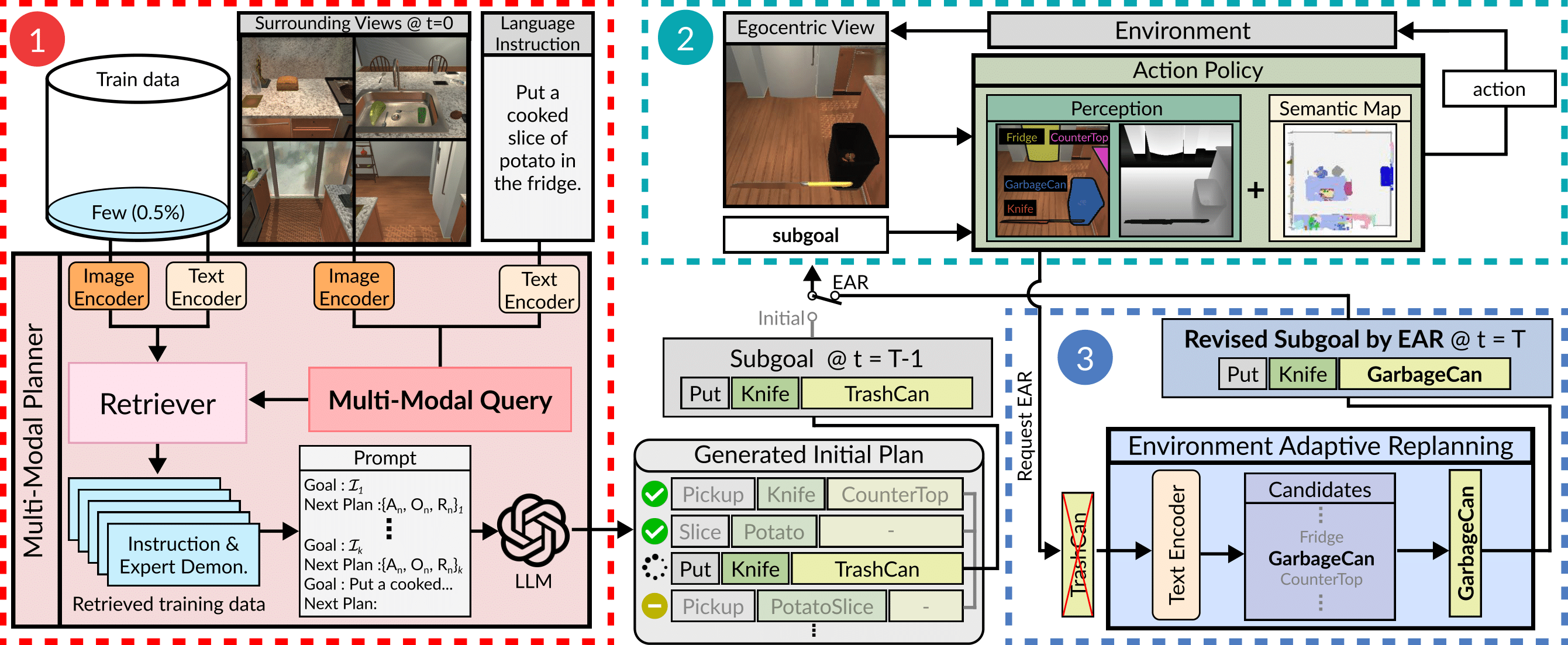
This is the natural next step after LLM-Planner. Instead of treating perception as a small object list, the planner uses multimodal cues to correct or revise the plan. For ambiguous or incorrect language instructions, visual evidence can change the generated subgoal sequence.
The takeaway is that replanning becomes more useful when it is grounded in perception, not only in conversation history.
When Replanning Becomes the Bottleneck
The papers above mostly make replanning more capable. But in long-horizon embodied systems, a new problem appears: replanning itself can become expensive.
Each replanning call may include:
- the original task instruction;
- the partial plan;
- action history;
- failure traces;
- scene summaries;
- object lists;
- human feedback;
- multi-agent coordination state.
As this context grows, a large-model replanning call can become slow and bursty. In a closed-loop system, slow replanning is not just an implementation detail. It delays execution, changes timing, and can create additional failures.
BRACE frames this as a control problem: when should the agent replan, how should it replan, and under what token and latency budget?
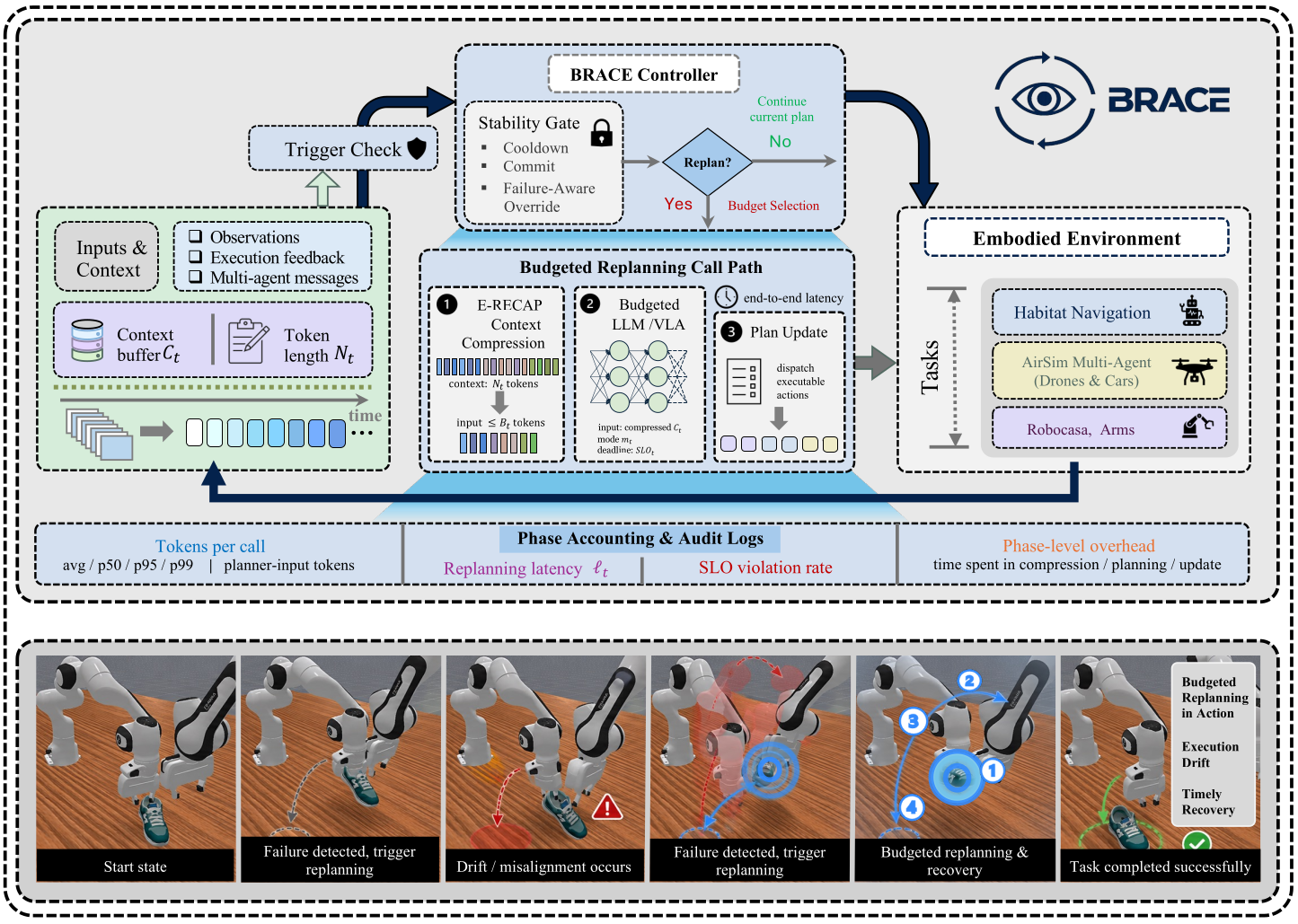
This shifts the question from “Can the agent recover if the plan fails?” to “Can the agent recover while respecting real-time constraints?”
For practical embodied agents, that distinction is crucial. A robot that replans correctly after 30 seconds may still fail the task if the world changes during those 30 seconds. A multi-agent system that replans too often can also create coordination delays.
A Paper-Grounded Taxonomy
The literature suggests a useful taxonomy:
| Replanning type | Main signal | Example |
|---|---|---|
| Reason-act replanning | Observation after an action | ReAct |
| Affordance-grounded replanning | Current action feasibility | SayCan |
| Feedback-language replanning | Natural-language feedback from detectors or humans | Inner Monologue |
| Object-grounded replanning | Observed objects and completed subgoals | LLM-Planner |
| Multimodal adaptive replanning | Visual state plus language instruction | FLARE |
| Budgeted replanning | Token, latency, and real-time constraints | BRACE |
These are not mutually exclusive. A deployable system may need all of them: perception to ground the plan, feedback to detect failure, memory to avoid repeating mistakes, and budgeting to decide whether another planner call is worth it.
What Makes Replanning Hard
Replanning sounds straightforward, but several design choices are easy to get wrong.
First, triggering is hard. Replanning too late leaves the agent stuck. Replanning too often causes instability and wasted computation.
Second, state summarization is hard. The replanner needs enough context to make a better decision, but not so much that every call becomes slow and noisy.
Third, granularity is hard. Sometimes the system should only repair one subgoal. Sometimes it should regenerate the whole plan. Sometimes it should stop and ask for help.
Fourth, grounding is hard. A replan based only on linguistic common sense can repeat the same mistake. The replanner needs current observations, affordances, and execution feedback.
Fifth, evaluation is hard. Task success alone is not enough. We also need to measure failed attempts, repeated replans, tail latency, human interventions, unsafe actions, and real-time deadline misses.
Why We Should Care
Replanning is central because it is where embodied AI becomes interactive. A one-shot plan can look impressive in a demo, but physical environments are partially observable, dynamic, and failure-prone.
The research direction matters for four reasons:
- Robustness. Replanning lets agents recover from execution drift and failed skills.
- Grounding. Replanning connects language-model reasoning to current observations and action feasibility.
- Safety. Replanning provides a mechanism to stop, revise, or ask for help when a plan becomes risky.
- Efficiency. Budgeted replanning makes planning cost part of the closed-loop policy rather than an afterthought.
The most useful embodied agents will not simply plan better. They will know when the current plan is still good, when it should be repaired, when a new plan is worth the cost, and when the safest action is to stop.
Further Reading
- ReAct: Synergizing Reasoning and Acting in Language Models
- SayCan: Do As I Can, Not As I Say
- Inner Monologue: Embodied Reasoning through Planning with Language Models
- LLM-Planner: Few-Shot Grounded Planning for Embodied Agents
- FLARE: Multi-Modal Grounded Planning and Efficient Replanning
- BRACE: When Replanning Becomes the Bottleneck