A Map of Robot World Models
World models are easy to describe loosely and surprisingly hard to define precisely. In one paper, the term may mean a latent dynamics model used for model-based reinforcement learning. In another, it may mean a video generator that predicts future frames. In a third, it may be an internal predictive representation inside a robot policy.
For robotics, the useful question is not “can the model generate a plausible future?” The useful question is:
Does the predicted future help the robot choose, improve, evaluate, or safely reject an action?
This post is a survey-guided map of that question. I mainly follow the 2026 survey World Model for Robot Learning: A Comprehensive Survey, and use several broader surveys to place it in context: Understanding World or Predicting Future?, A Comprehensive Survey on World Models for Embodied AI, and surveys on world models for autonomous driving.
A Practical Definition
In the broadest machine-learning sense, a world model is a model of how the world works. That is too broad to be useful for robot learning. A robot-facing definition should include three ingredients:
| Ingredient | Question | Example |
|---|---|---|
| State or observation | What does the agent know now? | camera image, depth, proprioception, object states, language instruction |
| Action or intervention | What does the agent do? | motor command, action chunk, high-level skill, navigation command |
| Future consequence | What changes because of that action? | next state, future video, reward, task progress, collision risk |
Under this view, a world model is not just a future image generator. It is a predictive model of agent-environment dynamics. Its value comes from being action-relevant.
This distinction matters. A video model may generate a beautiful future clip, but if the clip ignores the robot action, fails under contact, or cannot rank candidate behaviors, it is not very useful as a robotic world model. Conversely, a compact latent model may never render a photorealistic image, but still be valuable if it supports planning or policy improvement.
The Survey Lens
Several surveys look at world models from different angles:
| Survey | Main lens | Why it is useful here |
|---|---|---|
| Hou et al., 2026 | Robot learning and policy utility | The most direct map for robotics: policy, simulator, evaluator, video world model |
| Ding et al., 2024/2025 | General world-model taxonomy | Separates understanding the present from predicting future dynamics |
| Li et al., 2025 | Embodied AI | Frames world models around embodied perception, prediction, decision making, data, and metrics |
| Feng et al., 2025; Guan et al., 2024 | Autonomous driving | Shows how prediction and planning interact in safety-critical multi-agent scenes |
The common thread across these surveys is that world models are becoming less about passive prediction and more about decision support. The model must predict in a way that is useful for control.
Role 1: World Model as Part of the Policy
The first role is to connect future prediction directly to action generation.
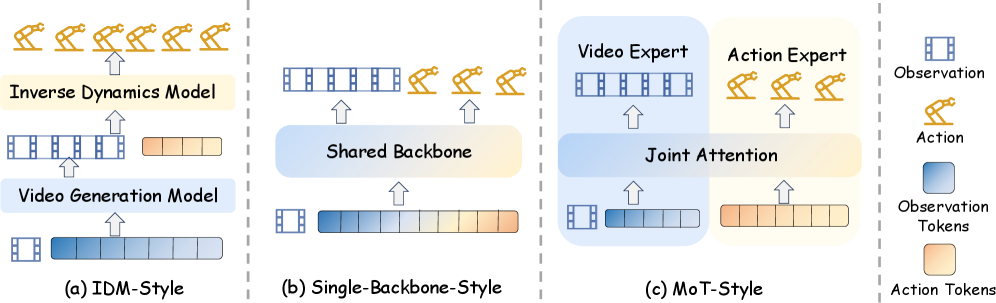
The survey separates several architectural patterns.
The most intuitive pattern is predict then act. A video generation model predicts a future observation, and an inverse dynamics model recovers the action that could produce it. This is easy to reason about: first imagine a target future, then infer how to get there. The weakness is that prediction and control are decoupled. If the future video is visually plausible but physically unhelpful, the action model inherits that mismatch.
A tighter pattern is a single shared backbone. Observation tokens and action tokens are processed together, so the model learns future prediction and action generation inside one representation space. This can make prediction more control-aligned, but it also makes the training objective harder to balance.
A third pattern uses specialized experts. One branch handles video or observation modeling, another branch handles action, and shared attention lets them interact. This is attractive because visual dynamics and motor control are related but not identical. The architecture can keep some specialization while still letting the two streams inform each other.
The most recent trend is latent world modeling. Instead of explicitly generating future images at inference time, the policy learns a compact predictive representation that captures future-relevant structure. This is important for deployment: a robot may benefit from future-aware training without paying the cost of generating future video at every control step.
Role 2: World Model as Simulator
The second role is to use the world model as an environment.
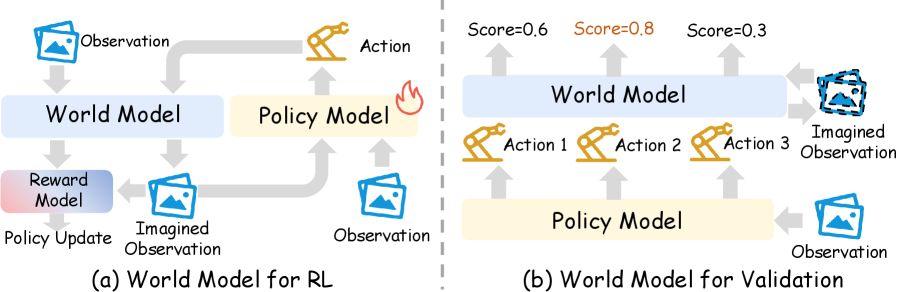
There are two different uses here.
First, a world model can support reinforcement learning in imagination. Instead of collecting every trajectory on a real robot, the policy can roll out inside a learned simulator, receive predicted rewards or termination signals, and improve from imagined experience. This connects modern robot learning back to classical model-based RL, but with stronger visual and multimodal predictors.
Second, a world model can act as an evaluator. The policy proposes several candidate actions or action sequences. The world model predicts their consequences. The system then selects, ranks, revises, or rejects candidates based on the imagined outcomes. This is not training inside the model; it is decision-time validation.
For real robots, the evaluator role may be more immediately practical than full imagined RL. A world model that can say “this action is likely to spill the cup” or “this path will collide” can improve safety even if it is not accurate enough to replace the physical environment for long rollouts.
Role 3: Robotic Video World Model
The third role is future visual generation, but with robot-specific constraints.
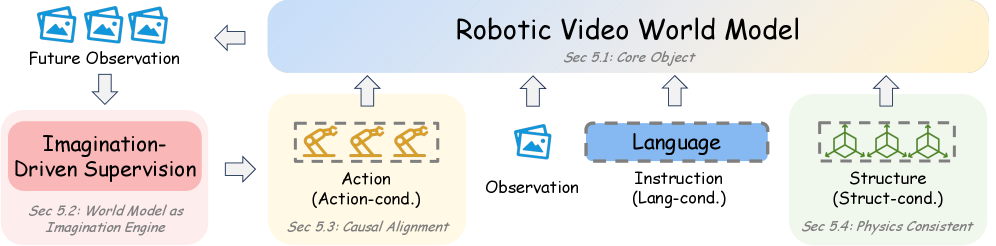
Robotic video world models are not generic text-to-video systems. They need to answer questions like:
- If the gripper pushes this block, where will the block move?
- If the instruction says “place it behind the bowl,” what future scene satisfies the language?
- If contact happens, does the generated sequence preserve geometry and physical consistency?
- If the robot uses a different embodiment, does the model still understand the action effect?
The survey highlights a progression:
- Future observation prediction: generate future frames from current observations.
- Imagination-driven supervision: use generated futures as training signals or visual plans.
- Action-conditioned generation: make futures depend explicitly on robot actions.
- Language-conditioned generation: align future prediction with task intent.
- Structure-aware generation: add geometry, object, contact, or interaction priors.
The shift is from “make the future look plausible” to “make the future useful for acting.”
Four Axes for Reading New Papers
When reading a new world-model paper, I find four axes useful.
1. Output Space
What does the model predict?
- Pixels or video frames
- Latent states
- Object-centric states
- 3D occupancy, geometry, or maps
- Rewards, termination, or task progress
- Symbolic predicates or relations
Pixel-space futures are interpretable and can preserve visual detail, but they are expensive. Latent futures are efficient, but harder to inspect. Structured futures are attractive for control, but require stronger assumptions about the world representation.
2. Action Conditioning
Does the model know what action caused the future?
This is a central difference between a robotic world model and a generic future predictor. In robotics, the same current image may lead to many possible futures depending on the action. If action conditioning is weak, the model may generate likely futures rather than controllable futures.
For manipulation, this often shows up in contact and object motion. For navigation, it appears as viewpoint and path consistency. For autonomous driving, it becomes multi-agent interaction: the ego vehicle’s plan changes how other agents may respond.
3. Coupling to the Policy
How close is the world model to the action policy?
- Separate predictor plus inverse dynamics
- Shared world-model/action backbone
- Mixture-of-experts interaction between perception and action
- Learned simulator for post-training
- Deployment-time evaluator or planner
This axis determines where computation happens. A world model can be used during training, during planning, during safety checking, or inside every action step. These are very different systems.
4. Evaluation Target
What proves that the world model is useful?
Standard video metrics are not enough. A robotic world model should be evaluated by action-relevant criteria:
- Does it improve task success?
- Does it reduce unsafe or wasted actions?
- Does it rank candidate actions correctly?
- Does it preserve physical consistency over long horizons?
- Does it generalize to new objects, layouts, embodiments, or instructions?
- Is the latency low enough for the control loop?
This is where many surveys agree: evaluation is still a bottleneck. A future video can look convincing while being wrong in exactly the way that matters for control.
What World Models Are Good For
A robot world model can help in at least five ways.
First, it can provide foresight. Before acting, the robot can estimate likely consequences.
Second, it can support planning. Candidate action sequences can be rolled out, compared, and revised.
Third, it can improve data efficiency. Imagined or generated trajectories can supplement expensive real robot data.
Fourth, it can enable policy evaluation. Instead of testing every policy variant on hardware, the system can use predictive rollouts as a filter.
Fifth, it can improve safety. A model that predicts collision, task failure, or irreversible changes can reject risky actions before execution.
The catch is reliability. A bad world model is not merely useless; it can make the robot confidently choose a bad action.
Open Problems
The survey literature repeatedly points to several open problems.
Long-horizon consistency. Small prediction errors compound. A model may be accurate for two frames and useless for twenty steps.
Physical grounding. Contact, force, occlusion, and object permanence remain difficult, especially in cluttered manipulation.
Causal controllability. The model must distinguish what changes because of the robot action from what merely looks likely in the dataset.
Efficiency. Explicit video rollouts can be too slow for real-time control, especially if the robot needs high-frequency feedback.
Evaluation. We still lack widely accepted metrics that connect predictive quality to downstream action success.
Policy-world-model co-evolution. If the policy improves using imagined rollouts, the world model may also need to improve from policy failures. Otherwise the policy can overfit to simulator mistakes.
A Simple Mental Model
For robotics, I would summarize the map this way:
| If the world model is used for… | It should answer… |
|---|---|
| Policy learning | What representation makes action generation easier? |
| Planning | Which future follows from this candidate action? |
| Simulation | Can imagined interaction replace some real interaction? |
| Evaluation | Which action or policy is likely to succeed? |
| Data generation | What useful experience is missing from the dataset? |
| Safety | What failure should be rejected before execution? |
That is why world models matter for robot learning. They are not just a way to make videos. They are a way to make action selection more informed.
Takeaway
The phrase “world model” is broad, but for robot learning the useful center is narrow: action-conditioned prediction that supports decision making. A good robotic world model does not only imagine what might happen. It helps the robot decide what to do next, how to train with less real data, how to evaluate candidate behaviors, and when not to act.
The field is moving from passive future prediction toward predictive control interfaces. The most important question is therefore not whether a model can generate a future, but whether that future is controllable, physically grounded, efficient enough, and useful for the policy.
Further Reading
- World Model for Robot Learning: A Comprehensive Survey. A 2026 policy-centric survey focused on robot learning, learned simulators, evaluation, robotic video world models, datasets, and benchmarks.
- Project page and maintained reading list for World Model for Robot Learning. Useful for tracking new papers after the survey cutoff.
- Understanding World or Predicting Future? A Comprehensive Survey of World Models. A broader survey that separates world models for understanding from world models for future prediction.
- A Comprehensive Survey on World Models for Embodied AI. A survey focused on embodied AI, taxonomy, data resources, metrics, and physical consistency.
- A Survey of World Models for Autonomous Driving. A driving-focused survey organized around future physical-world generation, behavior planning, and interaction between prediction and planning.
- World Models for Autonomous Driving: An Initial Survey. An earlier autonomous-driving survey that frames world models around future prediction and decision-making support.