Why TD3 Came Back: Fast Off-Policy RL for Humanoid Control
For a long time, the practical recipe for reinforcement learning in simulated robotics was simple: use massive parallel simulation, train with PPO, tune the reward, and wait for a deployable policy. PPO became popular for good reasons. It is stable, easy to scale across thousands of environments, and often forgiving enough for difficult locomotion tasks.
But PPO also has an awkward weakness: it is on-policy. Once the policy changes, old data quickly becomes less useful. This is acceptable when simulation is cheap and fully parallel, but it becomes limiting when we want sample reuse, demonstration-driven training, or real-world fine-tuning where every interaction is expensive.
FastTD3 is interesting because it asks a direct question: can a simple off-policy method become fast enough for modern humanoid control if we scale it the right way?

The Old Reputation of Off-Policy RL
Off-policy RL has always had a theoretical advantage: it can reuse data. Instead of throwing away past experience after every policy update, an off-policy method stores transitions in a replay buffer and learns from them repeatedly. This is attractive for robotics because robot data is expensive, and even simulated data can become costly when the task is complex.
The practical reputation was more mixed. In high-dimensional continuous control, off-policy methods such as DDPG, SAC, and TD3 can be sensitive to implementation details, critic instability, exploration noise, replay distribution, and reward scaling. PPO, by contrast, often gives a strong baseline with less engineering.
So the community’s default split became:
| Method Family | Practical Strength | Practical Weakness |
|---|---|---|
| PPO-style on-policy RL | Stable and easy to scale with many environments | Poor sample reuse and less natural for real-world fine-tuning |
| TD3/SAC-style off-policy RL | Reuses data and fits replay or demonstration settings | Historically harder to make fast and stable at humanoid scale |
FastTD3 does not claim that TD3 was secretly perfect all along. The more useful interpretation is that the surrounding systems context changed. Modern simulation stacks can run many environments in parallel, GPUs can handle large batches, and replay buffers can be fed with enough diverse data to make off-policy updates behave better.
What FastTD3 Changes
The core recipe is intentionally plain. FastTD3 is still based on TD3: a deterministic actor, twin critics, delayed policy updates, target networks, and replay-based learning. The difference is how the old algorithm is scaled and stabilized.
The key ingredients are:
- Parallel simulation. Many environments generate diverse experience quickly.
- Large-batch updates. The critic sees a broad slice of replay data in each gradient step.
- Distributional critic. Instead of predicting only a scalar value, the critic models a return distribution, which can make learning more stable.
- Careful hyperparameters. Noise schedules, update ratios, model size, replay size, and normalization details matter.
- Simple implementation. The method avoids complex asynchronous infrastructure, making it easier to reproduce and modify.
This combination is important because the bottleneck in robot RL is not only the algorithm. It is the whole training loop: environment throughput, batch construction, GPU utilization, replay freshness, and reward iteration speed.
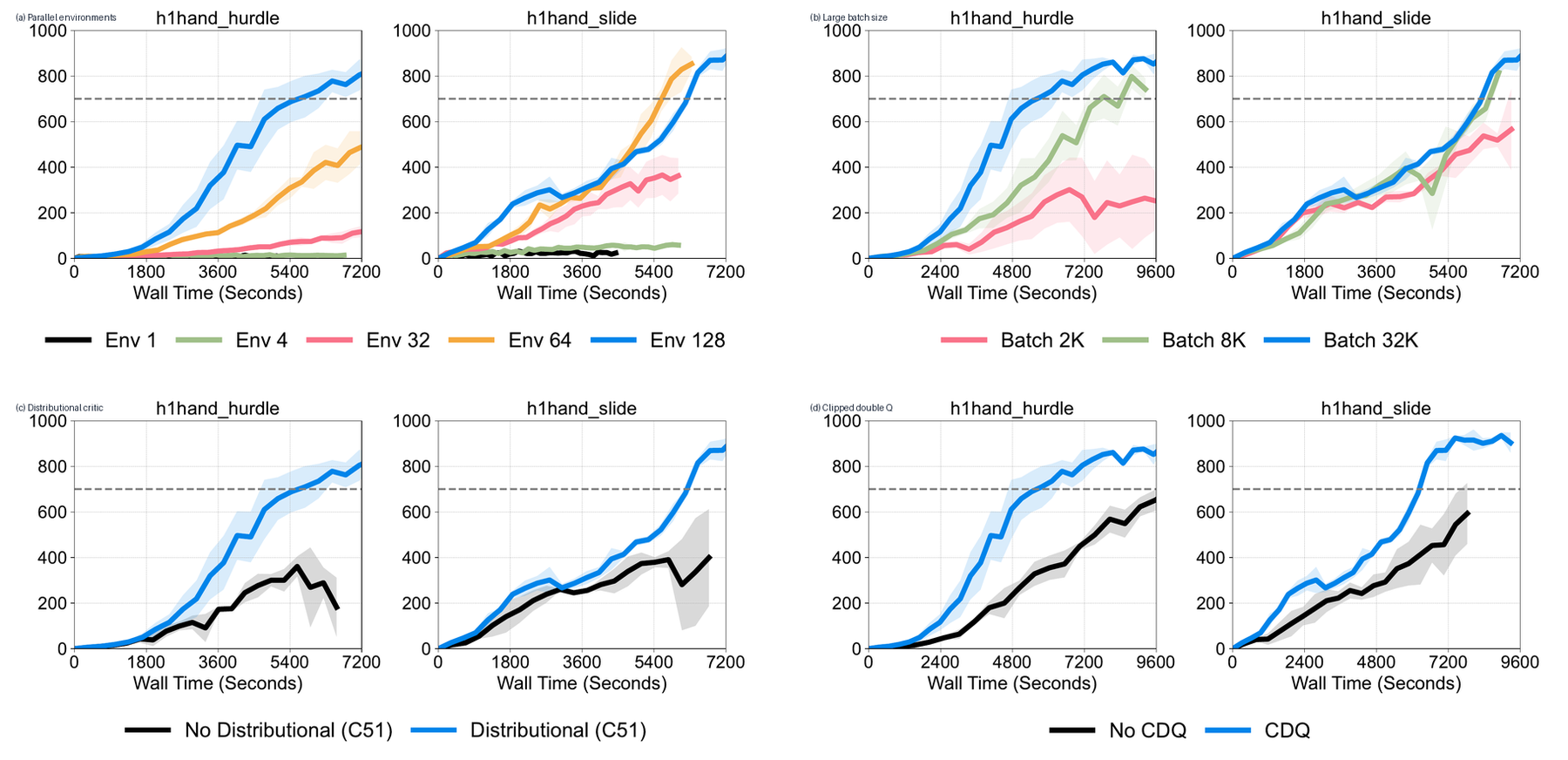
Why Parallel Simulation Helps Off-Policy RL
A replay buffer is only useful if the data distribution is healthy. If a robot collects data slowly from one narrow behavior distribution, the critic can overfit to a stale or biased slice of experience. With many parallel environments, the buffer receives more varied transitions: different states, resets, contacts, falls, recoveries, and terrain conditions.
This changes the role of the large batch. A large batch is not just a bigger tensor. It becomes a way to average over a more diverse slice of robot experience. That can reduce critic noise and make deterministic policy gradients less brittle.
The tradeoff is that “large batch” is not free. It requires enough environment throughput, enough replay data, enough GPU memory, and a training loop where batch construction does not become the new bottleneck. This is why FastTD3 is better understood as an algorithm-systems recipe rather than a single trick.
The Main Result
The reported result is striking because it targets wall-clock time, not just sample efficiency. FastTD3 solves a range of HumanoidBench tasks in under three hours on a single A100 GPU, and it is compared across HumanoidBench, IsaacLab, and MuJoCo Playground.
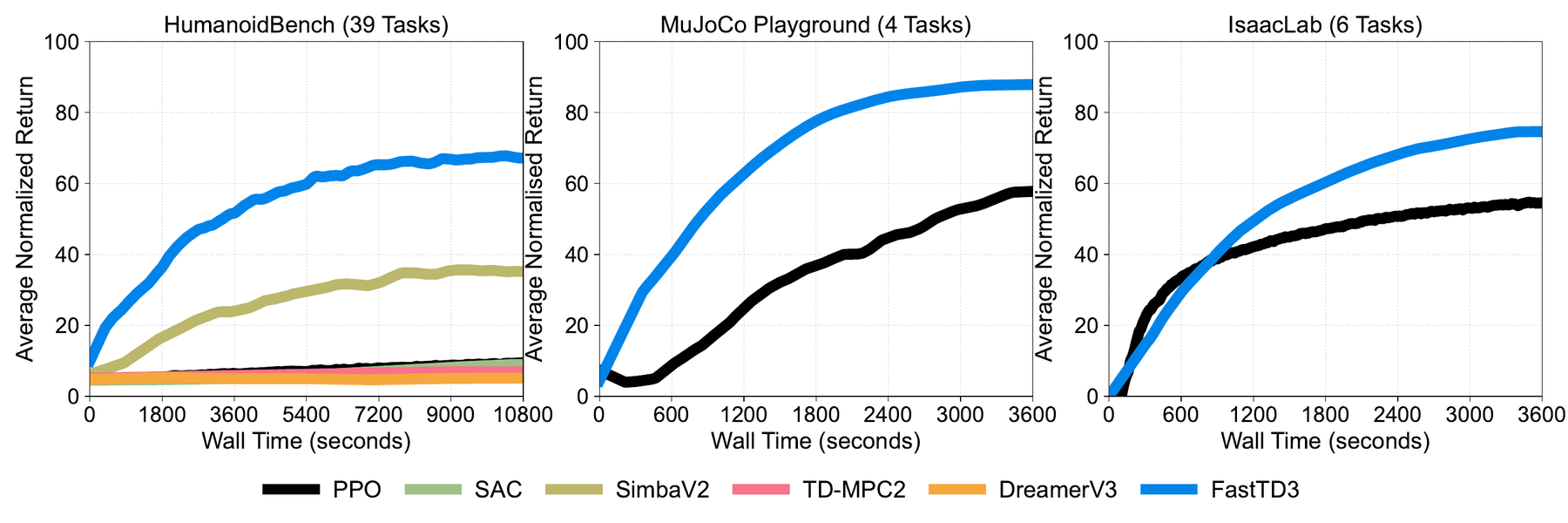
This matters because reward design in robotics is iterative. A practitioner rarely writes the final reward on the first try. They train a policy, inspect the gait, adjust penalties, re-run, and repeat. Cutting training time from tens of hours to a few hours changes how quickly a researcher can debug behavior.
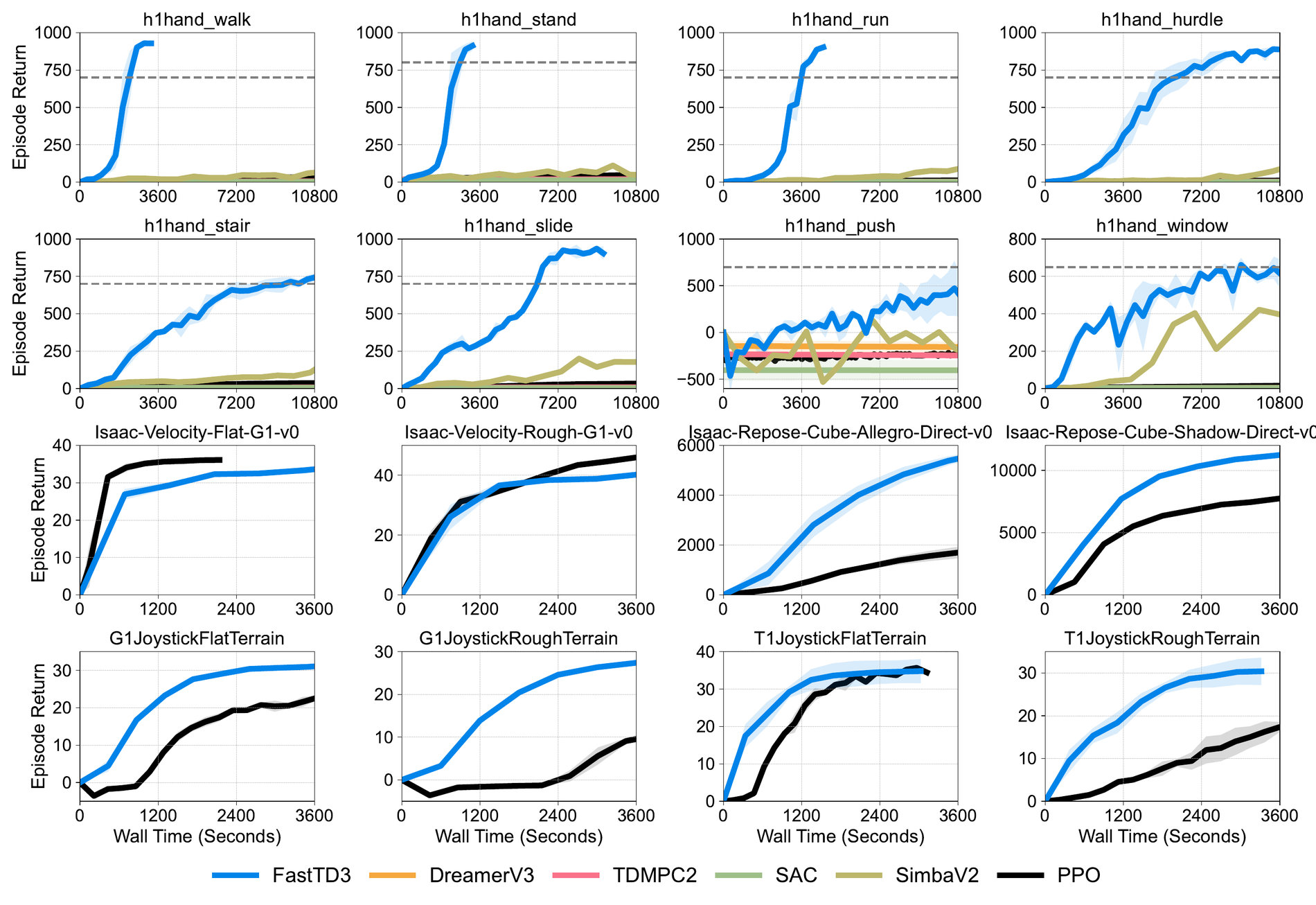
Why This Does Not Make PPO Obsolete
The wrong conclusion would be: “FastTD3 proves PPO is outdated.” That is too simple.
PPO remains a strong default when stability, implementation simplicity, and broad baseline comparability matter. It is also deeply embedded in many robot learning pipelines. FastTD3 instead shows that PPO is not the only practical wall-clock path for humanoid control.
The more precise lesson is:
- On-policy RL is still convenient when simulation is abundant and reward tuning is mature.
- Off-policy RL becomes more attractive when data reuse, demonstrations, or real-world fine-tuning matter.
- Large-scale simulation can help off-policy RL by feeding replay buffers with diverse data.
- Algorithm choice and reward design are coupled; the same reward may not produce the same behavior under different optimizers.
That last point is easy to miss. A reward that works well for PPO may produce poor gaits with FastTD3, and a reward tuned for FastTD3 may not suit PPO.
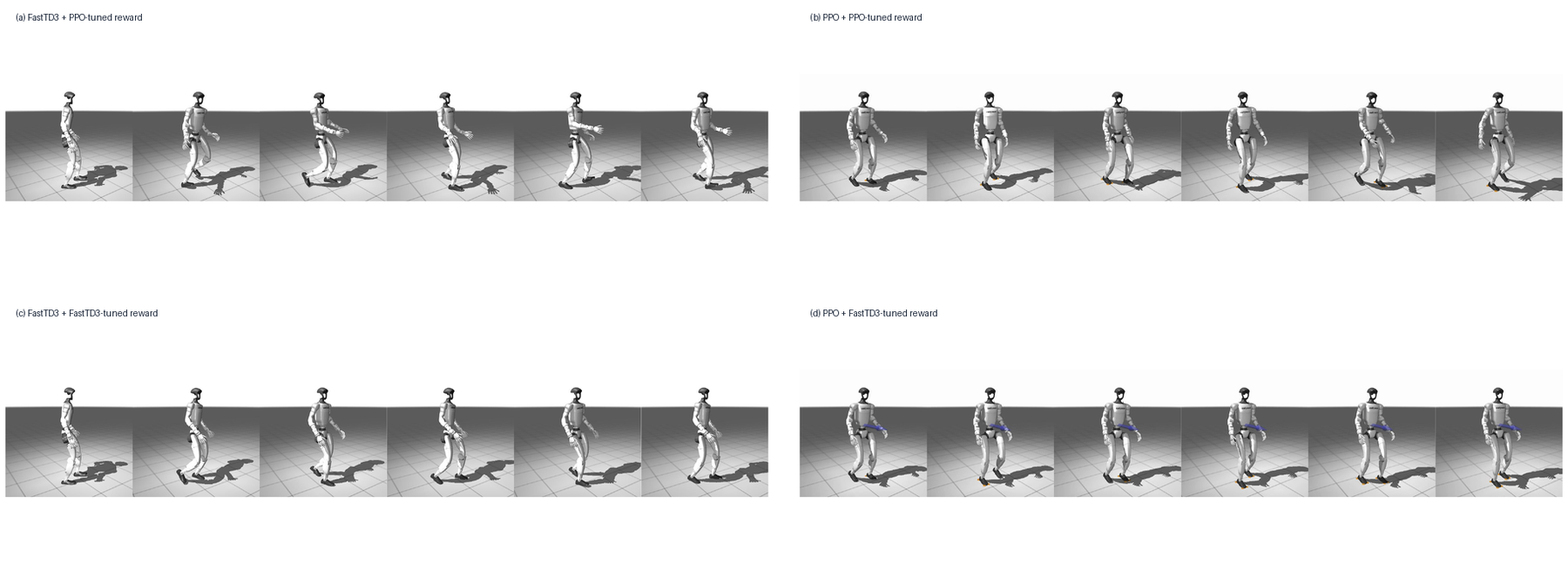
The Sim-to-Real Angle
Fast off-policy training is especially relevant for sim-to-real because it shortens the policy development loop. The paper includes a transfer example where a policy trained in MuJoCo Playground is deployed on a Booster T1 humanoid.

The key point is not that one algorithm solves sim-to-real by itself. The deployment still depends on task modeling, observation design, domain randomization, actuation details, safety checks, and reward tuning. FastTD3 makes the iteration loop cheaper, which can make those engineering steps less painful.
What I Would Watch Next
FastTD3 points to a broader direction: off-policy RL may become more useful for robotics when it is designed together with modern simulation and deployment infrastructure.
The next questions are practical:
- Can the same recipe handle richer observations, such as vision or tactile inputs?
- Can replay buffers combine simulation, human demonstrations, and limited real-world rollouts?
- How stable is the method under aggressive domain randomization?
- Can fast off-policy training support online adaptation after deployment?
- How much of the recipe transfers to multi-agent or distributed robot settings?
These questions matter because humanoid control is not only about one benchmark suite. It is about building an RL loop that can support repeated engineering decisions under realistic time budgets.
Takeaway
FastTD3 is useful because it reframes an old algorithm family in a modern systems setting. TD3 did not come back because deterministic policy gradients suddenly became easy. It came back because parallel simulation, large-batch training, distributional critics, and careful implementation made off-policy RL practical enough to compete on wall-clock speed.
For robotics, that is the real lesson: algorithm design and systems design are no longer separable. The best policy optimizer is not just the one with the cleanest objective; it is the one that fits the data pipeline, simulator, hardware, reward iteration loop, and deployment plan.