3D Scene Graphs for Embodied Reasoning
A robot needs more than pixels. It needs a memory of the world that supports questions such as:
- Where is the mug?
- What objects are on the table?
- Which door is connected to the hallway?
- Is the target object reachable?
- What can I move without colliding with something else?
Dense maps and point clouds help with geometry, but they are not always the right interface for reasoning. A planner often needs objects, relationships, regions, and affordances. This is where 3D scene graphs become useful.
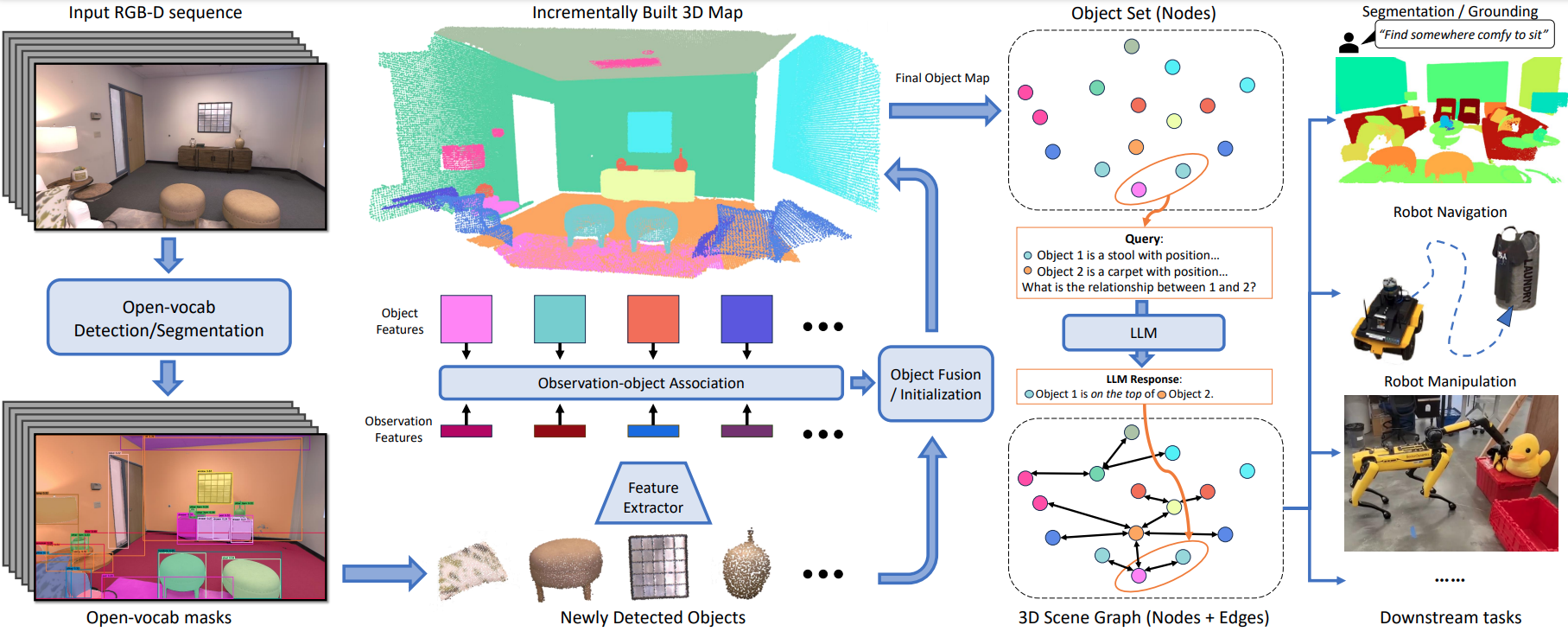
ConceptGraphs is a good entry point into this idea. It builds open-vocabulary 3D scene graphs from RGB-D observations, associating 2D foundation-model outputs across views and fusing them into object-centric 3D representations. The result is a map that can support perception, grounding, navigation, manipulation, and language-based queries.
From Maps to Scene Graphs
A conventional map might represent space as an occupancy grid, mesh, point cloud, or collection of visual features. These are useful for localization and obstacle avoidance, but they can be awkward for semantic reasoning.
A scene graph makes the structure explicit. It represents:
- nodes, such as objects, rooms, surfaces, or regions;
- attributes, such as category, color, size, pose, and affordance;
- edges, such as on-top-of, inside, next-to, connected-to, or reachable-from.
This representation is closer to the way many tasks are described. A command like “put the red cup on the table near the laptop” is naturally relational. It refers to objects, attributes, and spatial relations rather than raw pixels.
Why Open Vocabulary Matters
Closed-set perception systems assume a fixed list of categories. That is limiting for embodied agents. A home, lab, or warehouse can contain long-tail objects that were not in the training label set.
Open-vocabulary perception uses large vision-language models to recognize or retrieve concepts described in natural language. In a 3D scene graph, this means the robot can reason about objects using flexible language queries:
- “Find something comfy to sit on.”
- “Where is the power tool?”
- “Which container could hold a sponge?”
- “Move to the object next to the sofa.”
The graph does not need to know every category in advance. It can attach semantic embeddings or text-aligned features to objects, making the map searchable by language.
Why 3D Matters
Language grounding in 2D images is useful, but robots act in 3D. A robot needs to know not only that an object exists, but also where it is, how large it is, whether it is reachable, and how it relates spatially to other objects.
3D structure helps with:
- Viewpoint changes. The same object can be seen from different angles and fused into one entity.
- Occlusion reasoning. The robot can remember objects that are not currently visible.
- Navigation. The agent can plan paths through space, not just answer image questions.
- Manipulation. Object pose, support surfaces, and spatial constraints affect feasible actions.
- Memory. The map persists across time and supports long-horizon tasks.
This is one reason object-centric representations are attractive. They give planners a more stable interface than raw frame-level features.
What ConceptGraphs Adds
ConceptGraphs focuses on building an open-vocabulary graph-structured representation for 3D scenes. The rough pipeline is:
- Use generic 2D detection or segmentation to identify object regions in RGB-D frames.
- Extract semantic features using vision-language models.
- Project observations into 3D using camera poses and depth.
- Associate regions across multiple views.
- Fuse them into object-level 3D nodes.
- Use the graph for downstream grounding, planning, navigation, and manipulation tasks.
The important step is multi-view association. A chair seen from three camera poses should become one object node, not three disconnected detections. Once objects are fused, the agent can reason over persistent entities.
Why Graphs Help Planning
A planner does not always need every pixel. It may need a compact description:
| Planning need | Graph representation |
|---|---|
| “Find the mug” | Object node with open-vocabulary semantic feature. |
| “Go near the table” | Object or region node with 3D location. |
| “Pick the object on the shelf” | Relation edge between object and support surface. |
| “Avoid the fragile item” | Attribute or constraint attached to a node. |
| “Search the room systematically” | Region-level graph plus explored/unexplored state. |
This makes scene graphs a bridge between perception and symbolic planning. They are not a complete solution to robotics, but they expose the right handles for high-level reasoning.
Limitations
3D scene graphs are powerful, but they are not magic.
First, they depend on perception quality. Bad segmentation, wrong depth, or camera pose errors can produce incorrect nodes and edges.
Second, relationships can be ambiguous. “Near,” “inside,” “supporting,” and “reachable” may require task-specific definitions.
Third, graphs can become stale. If a human moves an object, the robot must update the map rather than trust old memory.
Fourth, open-vocabulary features are not the same as physical understanding. A model may label a tool correctly without knowing whether it is graspable, heavy, slippery, or safe to use.
Why This Direction Matters
Embodied reasoning needs memory that is both semantic and spatial. Pure language memory is not enough because robots need geometry. Pure geometry is not enough because human tasks are expressed through objects and relations.
3D scene graphs are one promising middle layer. They let robots build maps that can be queried by language, updated over time, and used by planners. For long-horizon tasks, that kind of persistent, object-centric world model is essential.
The broader lesson is simple: robots should not repeatedly rediscover the same scene from scratch. They should build structured memories that make future reasoning easier.