UniLab: Robot RL Benchmarking Is a Systems Problem, Not Just a Simulator Race
Modern robot reinforcement learning often starts with the same intuition: if we can run more simulated environments in parallel, we can collect more experience, train faster, and iterate more quickly. That intuition is mostly right. It is also incomplete.
The last few years have made GPU-resident simulation a dominant default for high-throughput robot learning. Isaac Gym, Isaac Lab, MuJoCo Playground, ManiSkill3, and Genesis all make a strong case that physics, rollout collection, and learning can benefit from staying close to accelerator hardware. But a training run is not only a simulator benchmark. It is a closed loop: environments generate experience, the learner consumes that experience, parameters are updated, collectors need fresh policy weights, and buffers move data across processor boundaries.
This is the core idea behind UniLab: efficient robot RL should be understood as a systems problem. The interesting question is not simply “GPU simulation or CPU simulation?” The better question is: which part of the training loop is actually limiting wall-clock progress, and how should the system allocate hardware to that bottleneck?

The Common Story: Faster Physics Means Faster RL
The usual argument for GPU-resident simulation is clean:
- Robot RL needs many environment steps.
- GPUs can step many environments in parallel.
- Therefore, putting physics on the GPU should make training faster.
This story explains a lot of recent progress, especially for massively parallel locomotion and manipulation workloads. It also explains why simulator throughput has become such a visible metric: environment steps per second is easy to measure, easy to compare, and easy to optimize.
But a full training run has more moving parts than a physics step. A robot RL system has at least three clocks:
| Clock | What It Measures | Why It Matters |
|---|---|---|
| Simulation clock | How quickly environments produce transitions or trajectories | Too slow, and the learner waits for data |
| Learning clock | How quickly the policy and value networks update | Too slow, and rollout data piles up or becomes stale |
| Synchronization clock | How often collectors, learners, buffers, and parameters block each other | Too much blocking can erase raw throughput gains |
A simulator can look fast in isolation but still fail to improve end-to-end training if it contends with the learner, forces expensive synchronization, or spends time moving data through an awkward runtime path. Conversely, CPU-side simulation can be useful if it generates enough data while leaving the GPU free for dense learning updates.
UniLab’s Framing
UniLab studies a heterogeneous organization: CPU-side batched physics, GPU-side learning, and a runtime layer that coordinates data movement, buffering, scheduling, and parameter synchronization.
This is not a new RL algorithm. The point is not to replace PPO, SAC, TD3, FlashSAC, or APPO. The point is to ask whether the same algorithms can train more efficiently when the system avoids making the GPU do both simulation collection and policy learning at the same time.
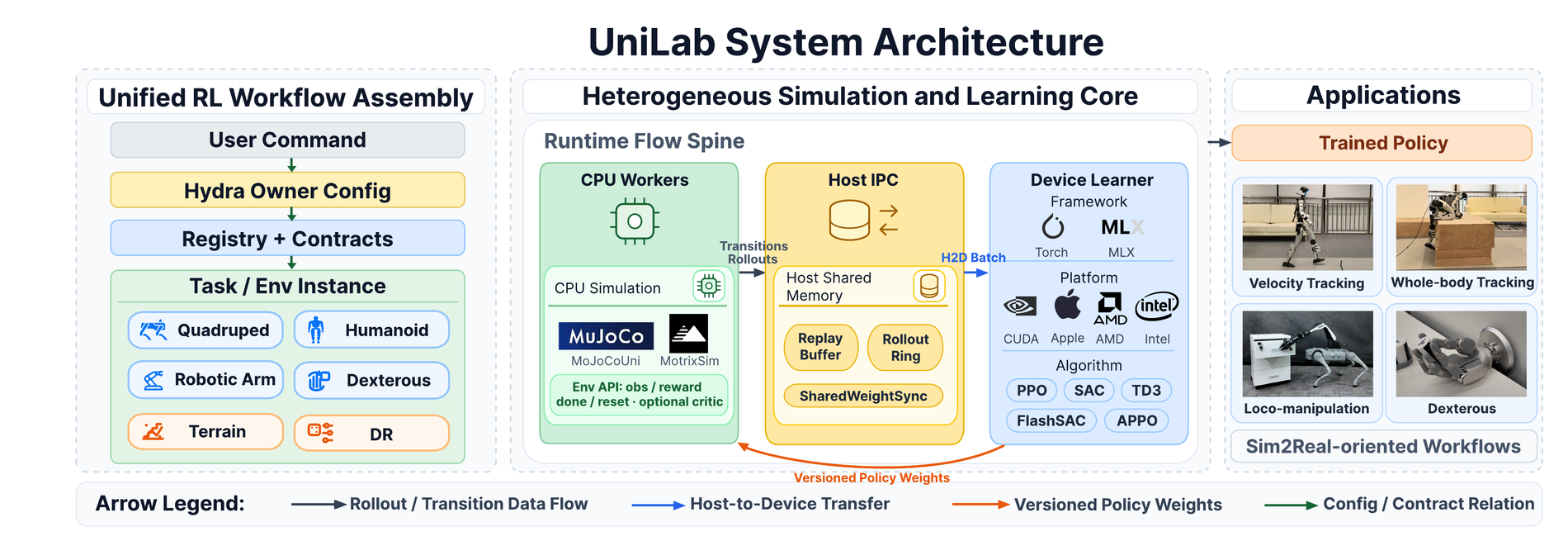
This design separates two ideas that are often bundled together:
Physics semantics are about the simulator model, solver behavior, contact handling, randomization, and task implementation.
Training throughput is about batching, scheduling, data transfer, buffering, update frequency, and synchronization.
The separation matters because “where physics runs” is only one decision. A training system can still be inefficient if it has fast physics but poor coordination. It can also be effective if CPU physics is fast enough and the GPU learner stays busy instead of waiting for rollout collection.
Why CPU Simulation Is Not Automatically a Step Backward
It is easy to treat CPU simulation as old-fashioned because GPU simulators have been so successful. UniLab pushes against that assumption in a narrower and more practical way: for some robot-control workloads, batched CPU physics can provide enough simulator-side capacity to support an efficient heterogeneous training loop.
The advantage is not that CPUs are universally faster. They are not. The advantage is role separation.
When simulation and learning share the same GPU, the system may create resource contention: the collector wants accelerator time to step environments, while the learner wants accelerator time to run neural updates. If the workload is arranged so that CPU workers can keep generating data, the GPU can focus on the learner. In replay-based or loosely coupled training, this can let collection and learning overlap in wall-clock time.
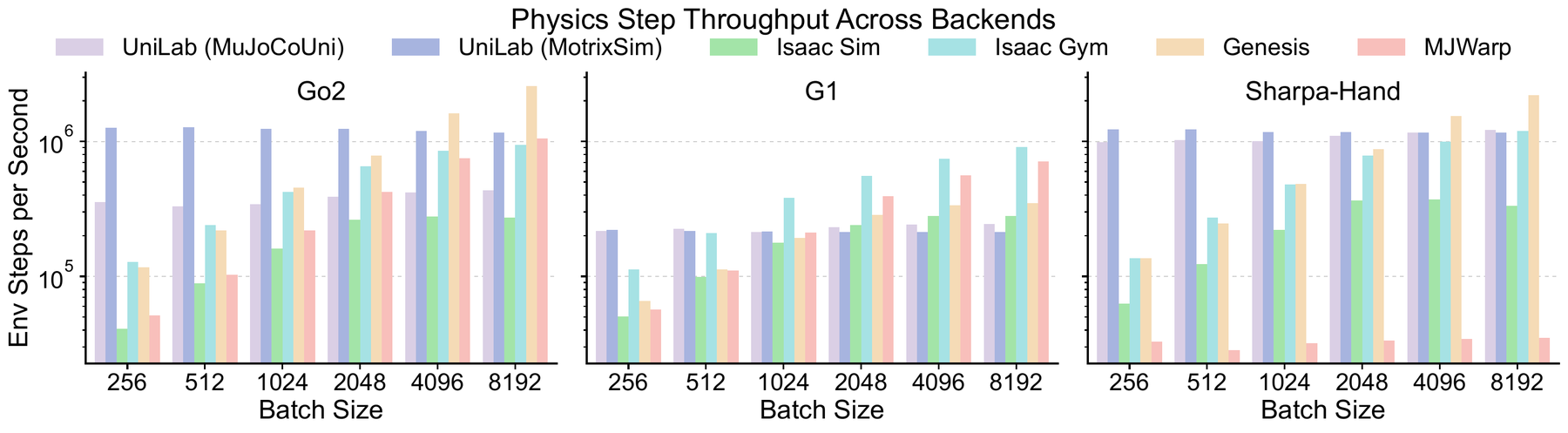
This is also where task type matters. Simple locomotion, whole-body motion tracking, dexterous hand manipulation, and manipulation-locomotion do not stress the system in the same way. Contact-rich tasks can shift the balance between simulator cost, learner cost, and synchronization cost.
Where the End-to-End Gain Comes From
The most important word here is end-to-end. A robot RL benchmark should not only ask which backend has the highest isolated simulator FPS. It should ask how long it takes to reach a useful training outcome under a controlled setup.
UniLab reports that its CPU-simulation / GPU-learning organization improves end-to-end training efficiency by roughly 3-10x across several representative tasks and algorithms under the studied hardware settings. The exact number is less important than the mechanism: gains appear when the runtime can decouple collectors from the learner and avoid making one stage wait unnecessarily for the other.

For synchronous PPO, the room for overlap is limited because rollout collection and policy update are tightly coupled. For APPO, SAC, TD3, and FlashSAC-style training, the system has more freedom: collectors can keep filling buffers while the learner consumes batches on the GPU. That is where heterogeneous placement becomes more than a hardware trick; it changes the timing structure of the training loop.
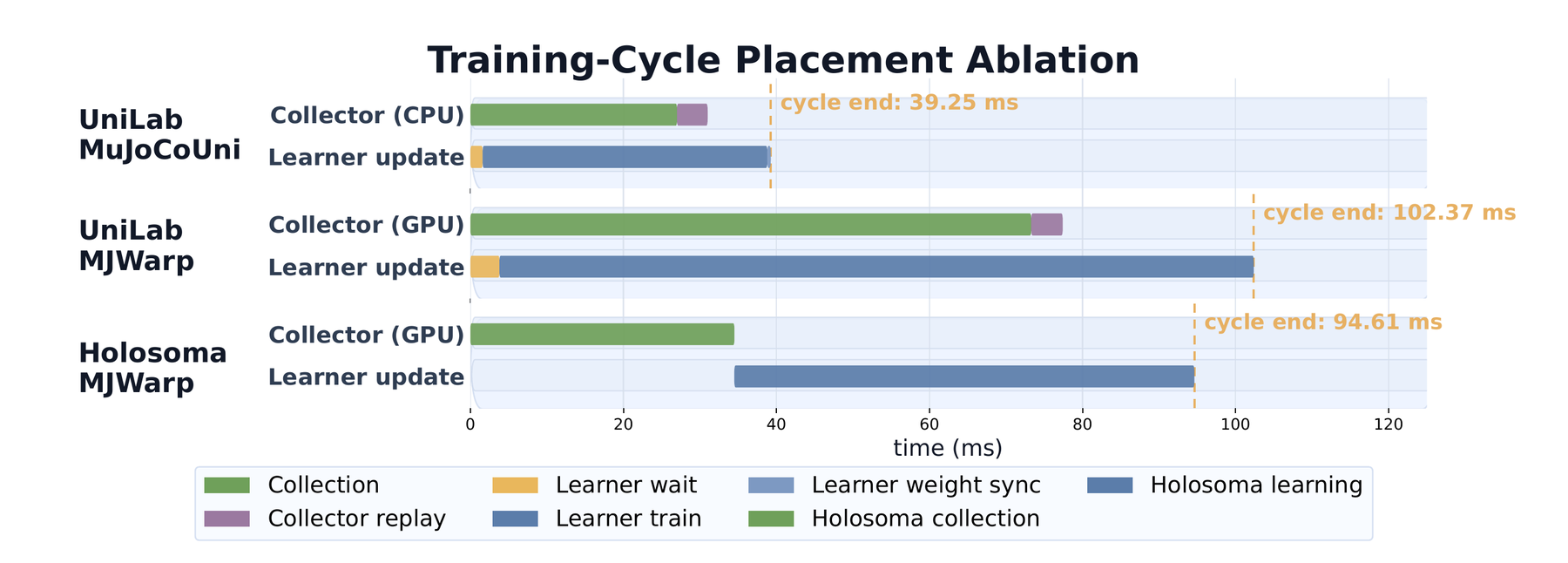
What Others Are Doing
UniLab sits in a larger ecosystem rather than replacing it.
GPU-native robot learning systems such as Isaac Gym, Isaac Lab, MuJoCo Playground, ManiSkill3, and Genesis show that accelerator-resident physics can be extremely effective. They are especially natural when the whole workload is designed around GPU batches and the simulator stack is mature for the task.
General RL infrastructure such as EnvPool, Tianshou, RLlib, and PufferLib shows another long-running tradition: CPU-side vectorized or distributed environment execution can be very effective when the runtime is engineered carefully.
UniLab’s position is closer to a systems counterexample than a universal replacement. It says: GPU-resident simulation is a strong path to efficient robot RL, but it is not the only path. If CPU-side batched physics is fast enough, and if the runtime makes collection and learning overlap, a heterogeneous architecture can be competitive or better for certain workloads.
That distinction is important. A useful systems paper should not turn one successful configuration into a law of nature.
What Makes a Robotics Benchmark Useful?
A good benchmark should help researchers make decisions. For robot RL systems, that means it should report more than a single throughput number.
Here is the checklist I would use when reading or designing a benchmark:
- End-to-end wall-clock time. How long does it take to reach a target reward, success rate, or policy quality?
- Simulator throughput. How many environment steps can the backend produce, and under what task complexity?
- Learner utilization. Is the GPU busy updating the model, or is it waiting for rollout data?
- Synchronization cost. Do collectors block on policy weights? Does the learner block on new rollouts?
- Data movement. Are host-device transfers hidden behind useful work, or do they create visible stalls?
- Algorithm coverage. Does the system only look good for one timing pattern, or does it support on-policy, off-policy, and asynchronous variants?
- Task diversity. Does it cover multiple embodiments and contact regimes, or only the easiest workload?
- Portability. Does the design depend on one vendor-specific stack, or can the learner and simulator be decoupled across platforms?
This is why I like the UniLab framing. It forces the benchmark to look at the whole loop. It also gives a more honest answer when performance differs across tasks: the system did not “get slower” in the abstract; a particular stage became the bottleneck.
Contact-Rich Tasks Make the Point Concrete
Dexterous hands are a good reminder that robot learning is not only about clean locomotion curves. Contact-rich manipulation stresses collision handling, solver behavior, observation design, reset logic, and policy robustness. It also makes the system question more visible: if data generation is expensive or irregular, the learner’s timing becomes harder to keep smooth.



These images are not just decoration. They represent the kind of workload where a benchmark must care about contact complexity, backend semantics, rollout throughput, and learning schedule at the same time.
A Practical Takeaway
For robot RL, “use the fastest simulator” is not wrong, but it is too shallow. The real target is a balanced training loop:
- Generate enough experience.
- Keep the learner busy.
- Avoid unnecessary blocking.
- Hide data movement when possible.
- Match the runtime design to the algorithm’s data dependency.
- Measure wall-clock progress, not only isolated throughput.
UniLab is useful because it gives a concrete example of this broader view. It does not say GPU simulation is obsolete. It says that efficient training depends on the organization of the whole simulation-learning loop, and that heterogeneous CPU-simulation / GPU-learning is a legitimate point in the design space.
That is a healthier way to think about robotics infrastructure. Instead of asking which processor should own the entire pipeline, ask what each part of the pipeline is good at, where the true bottleneck is, and whether the system lets different stages work at the same time.
Further Reading
- UniLab project page: github.com/unilabsim/UniLab
- Representative GPU-resident robotics systems: Isaac Gym, Isaac Lab, MuJoCo Playground, ManiSkill3, and Genesis.
- Representative general RL infrastructure: EnvPool, Tianshou, RLlib, and PufferLib.